Redis五大基本数据类型底层数据结构详解
Redis底层数据结构分享
一、Redis6、Redis7新特性
1.1 Redis6
Redis6.0于2020 年 5 月 2 日发布,已经经过了两年,也是目前使用人数最多的版本。
- 支持多线程处理网络数据的读写和协议解析。(IO处理多线程,执行命令仍单线程)
- 推出RESP3协议,提供更多的语义化响应,以开发使用旧协议难以实现的功能,实现 Client-side-caching(客户端缓存)功能。
- 支持SSL
- 提升了RDB日志加载速度
- 引入了 ACL(Access Control List),引入了用户概念,可以给每个用户分配不同的权限来控制权限。
- ···
1.2 Redis7
Redis7.0于2022年4月24日发布,至今最新已更新到7.0.4版本。
- 多AOF文件支持,为两种类型:基本文件(base files)、增量文件(incr
files),在
redis.conf文件中配置 config命令增强,CONFIG GET/SET可以一次处理多个配置- 限制客户端内存使用,
redis.conf中通过maxmemory-clients配置 listpack紧凑列表替代ziplist的新数据结构,在 7.0 版本已经没有 ziplist 的配置了- ···
Redis源码可到http://download.redis.io/releases/下载,以Redis6.2.6源码为例。
二、五大基本数据类型底层结构
使用OBJECT ENCODING key可以查看五大数据类型的底层数据结构
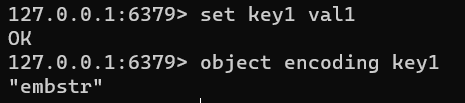
2.1 String
2.1.1 String简介
String是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
实战场景
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- session:常见方案spring session + redis实现session共享
2.1.2 String底层结构
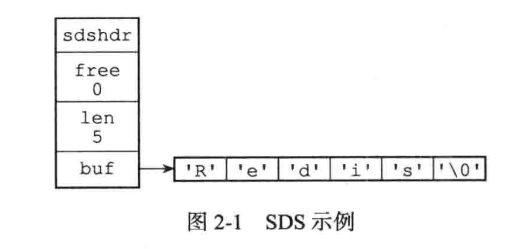
Redis中字符串非C语言中的字符串,自己构建了简单动态字符串(Simple dynamic String)SDS,并作为默认字符串表示。
根据源码可以看到SDS定义了5种数据结构:sdshdr5,sdshdr8, sdshdr16,sdshdr32,sdshdr64,结构都相同,不同的是字节长度。
1 | |
为什么需要使用5种数据结构呢?因为redis会根据字符串的长度使用不同的header头,从而达到内存优化的目的。
- 当字符串的长度
len < 2^5且不为空的字符串的时候使用的是sdshdr5;
- 当字符串的长度
- 当字符串的长度
2^5 >= len < 2^8或者字符串为空的时候使用sdshdr8;
- 当字符串的长度
- 当字符串的长度
2^8 >= len < 2^16时候使用sdshdr16;
- 当字符串的长度
- 当字符串的长度
2^16 >= len < 2^32并且系统是64位的时候使用sdshdr32;
- 当字符串的长度
- 其他的情况使用
sdshdr64;
- 其他的情况使用
根据SDS的长度,如果进行追加,会进行自动扩容,类似Java的ArrayList扩容。
2.1.3 SDS动态扩容
SDS的动态扩容可以从下面的源码可以看出:
1 | |
- 初始分配时alloc值和字符串实际长度相同。
- 扩容时:
- 剩余空间足够,不进行扩容。
- 空间不足时并且
len+addlen长度(newlen)小于1M(1024Byte)时,扩容为原来的2倍 - 空间不足时并且新的字符串的长度(newlen)大于
1M(1024Byte)时,增加1M空间。
2.1.4 内存不对齐
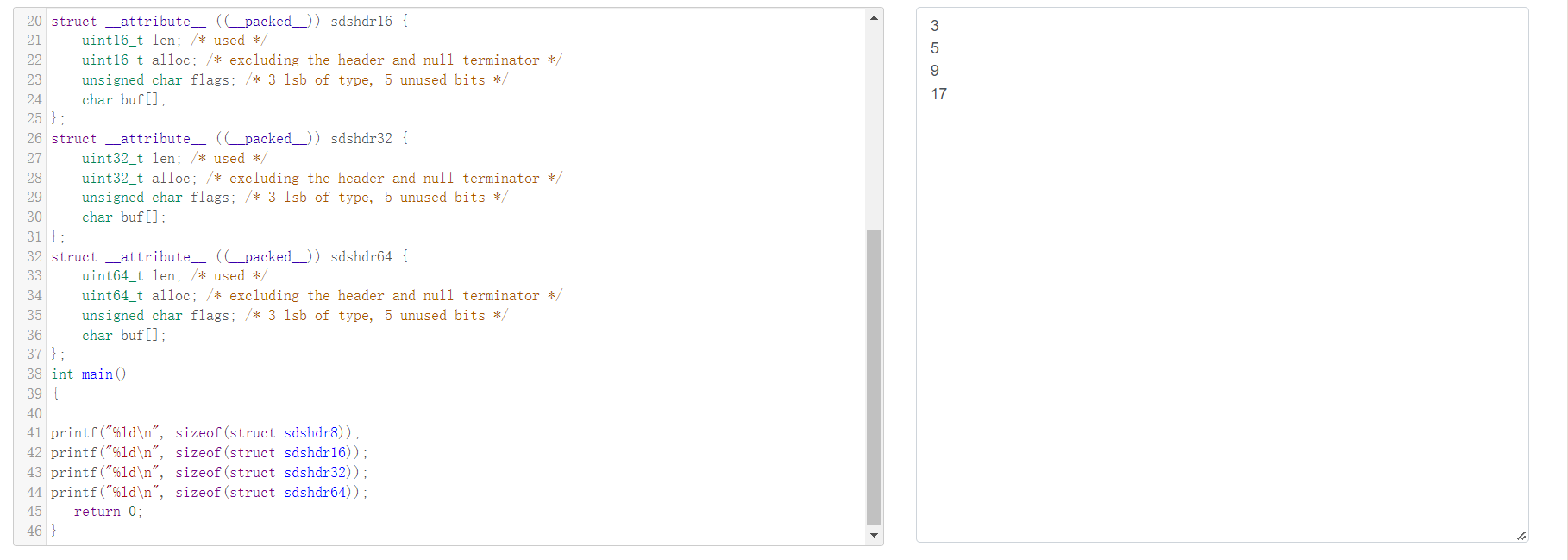
注意到:SDS定义时,参数里有__attribute__ ((__packed__)),告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。
CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问,所以数据结构应该尽可能地在自然边界上对齐,如果访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存访问仅需要一次访问,内存对齐后可以提升性能。
内存对齐后CPU访问内存的速度会大大提升,那为什么SDS选择看似的内存不对齐呢?是为了节省那缺省的字节空间吗?
1 | |
可以看到
如果SDS内存对齐,那么SDS数据结构就如下:
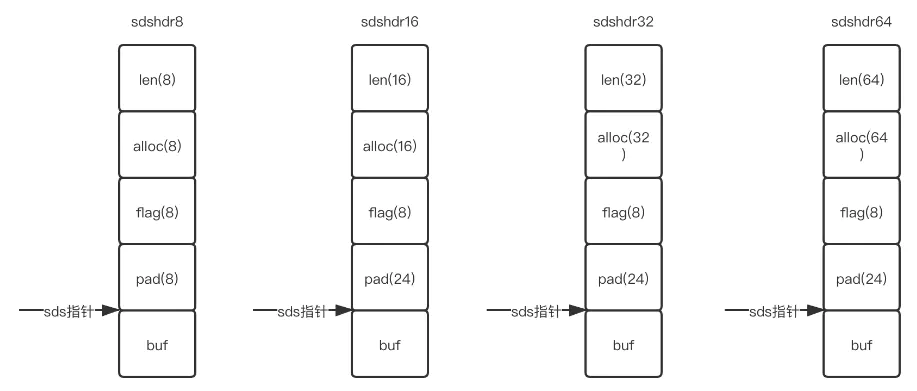
可以看到多了pad对齐项。从而如果要通过buf - 1访问flag是不可能的了,因为不同类型对齐字节数也不同,还需要进行类型判断,并且不同的系统可能有不同的对齐方式。
为了应对内存不对齐,Redis在malloc基础上封装了zmalloc将内存分配收敛,并解决了内存对齐的问题。
zmalloc分配内存源码如下:
1 | |
通过阅读源码发现,zmalloc基于malloc,创建了自己的内存池,对内存池进行操作,相比于原生malloc,内存池可以极大地提升内存分配和释放速度,并且可以防止内存泄漏。并且在内存池分配内存前,malloc(MALLOC_MIN_SIZE(size)+PREFIX_SIZE)也进行了内存对齐。而内存池在设计的时候是需要内存对齐的,不然会出问题。
zmalloc是jemalloc的封装,jemalloc作为Redis的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。
所以Redis并不是没有进行内存对齐,而是通过内存池的方式进行内存对齐,极大减少了内存碎片的产生,同时对内存操作的效率也得到了很大的提升。
2.1.5 为什么不使用C语言的字符串呢?
可以直接获取字符串长度,C语言中通过遍历计数实现,O(n).
不存在缓冲区溢出。对于C语言中
strcat()拼接如果空间不够会导致缓冲区溢出,SDS会通过len和alloc判断空间是否足够,如果不够就会进行相应的扩展。减少修改字符串的内存重新分配。
二进制安全
C语言中通过空字符作为字符串终止标志,而图片等二进制文件内容可能包含空串,因此无法正常读取,SDS都是以二进制来处理buf中的内容,以len属性来判断字符串的终止。
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
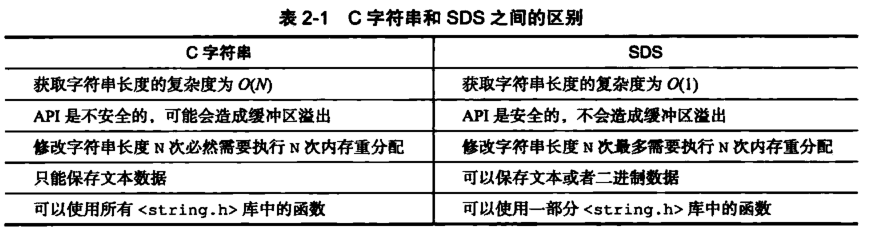
2.1.6 embStr和SDS有什么关系?
对于Sting字符串对象的编码可以是int,raw或者embstr。embstr保存长度小于44字节的字符串,是专门保存短字符串的一种优化编码、raw保存长度大于44字节的字符串。他们背后都使用SDS存储。
为什么是44字节?每个数据类型都有一个redisObject包含。
1 | |
可以算出一个RedisObject至少包含19字节,Redis认为超过64字节的String就属于长字符串,加上字符串结尾\0一个字节,所以相减后就得到一个embstr最大支持的字符串长度为44字节。
2.2 List
Redis3.2之前使用双端链表实现List,Redis.2后引入了quicklist快表作为List的底层实现。但也还保留了链表的实现。
使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
- 使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
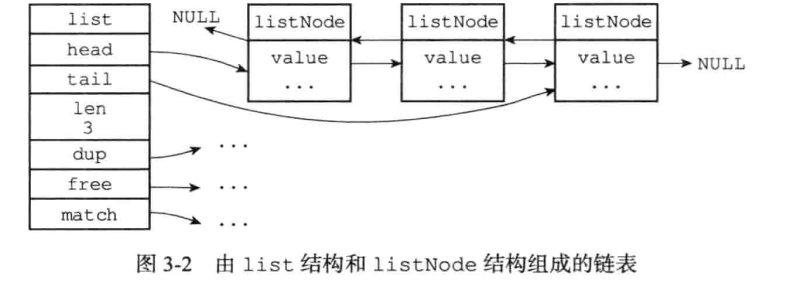
Redis自己实现了链表
1 | |
1 | |
提供了操作链表的函数
Redis链表特性:
①、双端:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
②、无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。
③、带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。
④、多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
2.2.1 QuickList快表
1 | |
QuickList 结构如下:
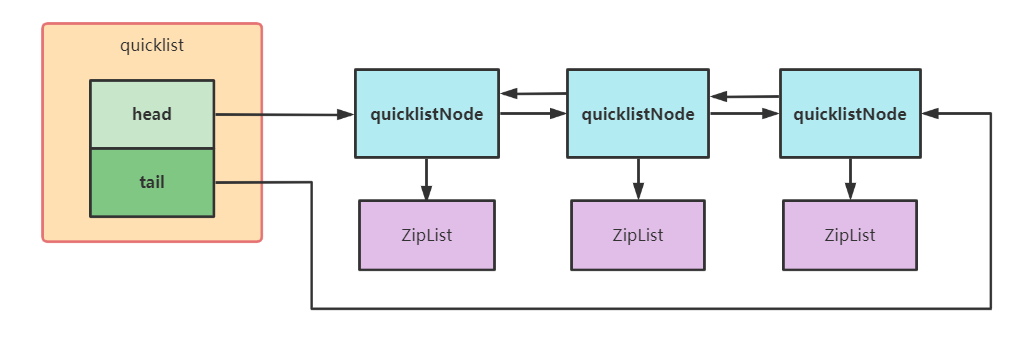
QuickList的优点有:
- 双向链表能在头尾在
O(1)下找到一个元素,若是在中部查找则平均复杂度也只是O(N),N
是
Entry的个数。 - ziplist 使用了紧凑布局和可变编码方式大大降低了内存的使用。这就是 quicklis 作为 List 首选的实现方案。
QuickList查询时间复杂度为O(n),因为访问两端时间复杂度为O(1),所以用作队列进行push、pop时效率非常高。
2.3 Hash
Dict由两种数据类型实现:压缩列表ZipList和哈希表HashTable.
当数据量小且存储的为整数值或短字符串时使用ZipList作为Hash,其他情况使用HashTable。
ZipList压缩列表顾名思义非常节省内存。
Hash中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。C 语言中没有内置这种数据结构的实现,所以字典依然是 Redis自己构建的。Redis 使用哈希表作为底层实现。
相比String存储,更节省空间,且使用于存储对象信息、能对对象其中的字段进行修改。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
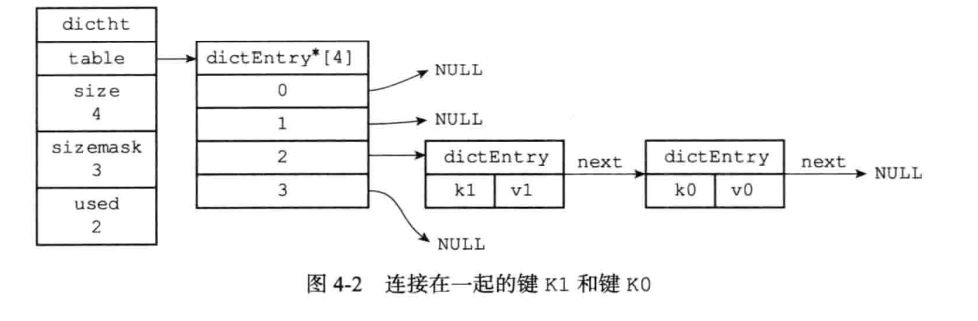
2.3.1 哈希表定义
1 | |
一个哈希表dictht结构图如下:
2.3.2 字典 Dict
1 | |
type是一个指向dictType的指针,通过自定义的方式使得dict的key和value能够存储任何类型的数据。
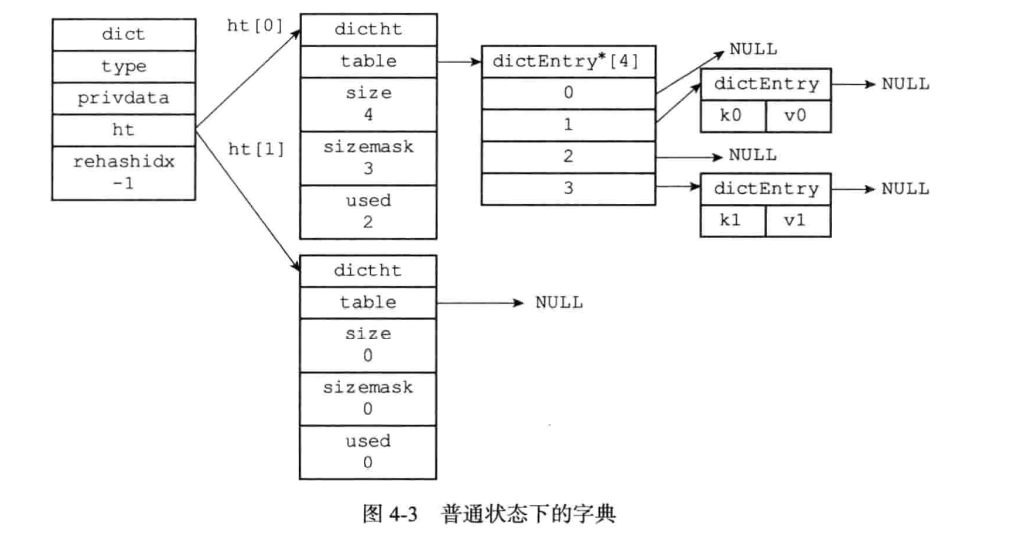
注意到一个字典Dict有两个哈希表dictht,是为了实现渐进式
rehash。
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
只有在rehash的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。
一个没有进行rehash的字典Dict结构如下:
2.3.3 哈希算法与哈希冲突的解决
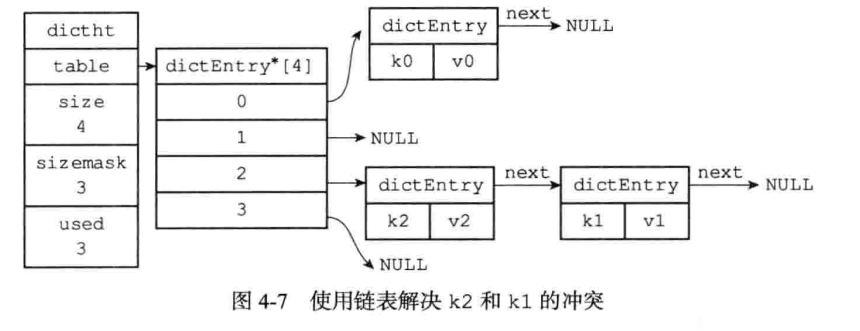
哈希表最重要的就是哈希算法,它决定了元素存放的位置。
Redis使用murmurHash2哈希算法,这种算法即使输入的键是有规律的,算法仍能给出一个很好的随机分布性,计算速度非常快,使用简单。murmurHash2哈希算法源码可以查询阅读。
Dict的索引值计算过程如下:
1 | |
有哈希算法就会产生哈希冲突,Redis解决哈希冲突的方式是使用了链地址法。和JDK1.7 HashMap的哈希冲突解决方法一样,如果产生冲突,采用头插法插入到链表的头部。
2.3.4 扩容与收缩(rehash)
扩容代码如下:
1 | |
阅读源码可知:
Dict初始化容量为4.- 如果负载因子大于1,则扩容为原来的两倍。
- 哈希表的容量始终为
2的n次方。
当哈希表保存的键值对太多或者太少时,就要通过rehash(重新散列)来对哈希表进行相应的扩展或者收缩,这个时候之前介绍的ht[1]就开始起作用了,rehash具体步骤:
- 为
ht[1]分配空间,同时持有ht[0]和ht[1]。
1、如果执行扩展操作,会基于原哈希表创建一个大小等于
ht[0].used*2的哈希表ht[1]。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表ht[1]。
2、重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
3、所有键值对都迁徙完毕后,释放原哈希表的内存空间。
- 触发扩容的条件:
1、服务器目前没有执行 BGSAVE 命令或者
BGREWRITEAOF 命令,并且负载因子大于等于1。
2、服务器目前正在执行 BGSAVE 命令或者
BGREWRITEAOF 命令,并且负载因子大于等于5。
因为在执行BGSAVE命令或BGREWRITEAOF命令的过程中,Redis需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制( copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。和Java HashMap类似。
1 | |
源码中提到当当前使用量小于容量1/10时,会进行收缩。
rehash源码如下:
1 | |
rehash图如下:
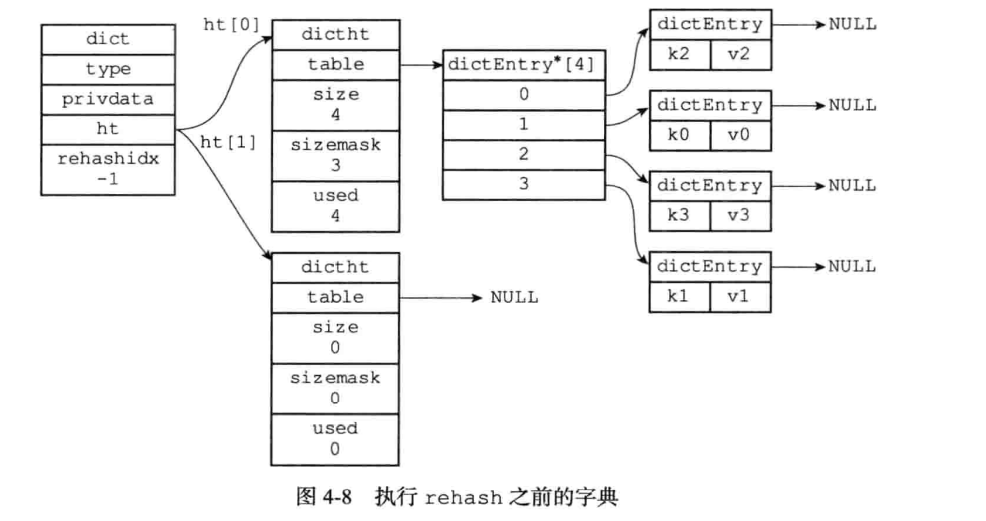
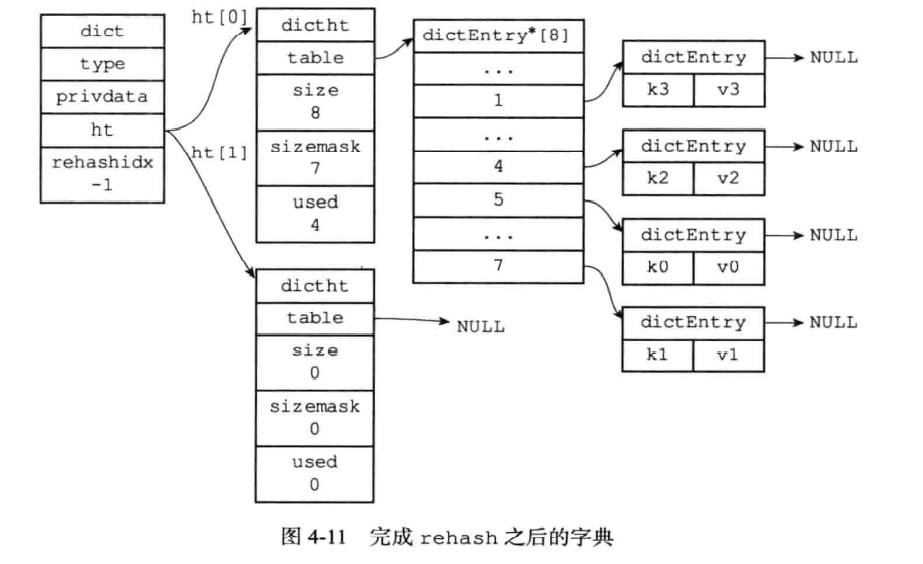
如果ht[0]的节点数量非常多,导致一次rehash需要非常长的时间,这样就会影响客户端操作响应时间,因此使用渐进式rehash可以解决这个问题
渐进式rehash,即在上述rehash过程中,根据源码可以看到,可能随时暂停,因为需要响应客户端的操作。相比之下需要多维持一个rehashidx来表示rehash工作正在进行中。
渐进式rehash 的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash而带来的庞大计算量。
具体来说就是在渐进式rehash期间,如果有删改查操作时,如果index大于rehashindex,访问ht[0],否则访问ht[1]。对于添加操作来说,只会在ht[1]上添加,可以避免一次复制。
2.4 Set
Redis的集合(Set)有两种实现:整数集合(IntSet)和哈希表hashtable.
当集合保存的元素都是整数值时会采用IntSet,当集合对象保存的元素数量超过512时会转为
Dict保存,数据作为key,对应的Value都为null,类似Java的HashSet实现。
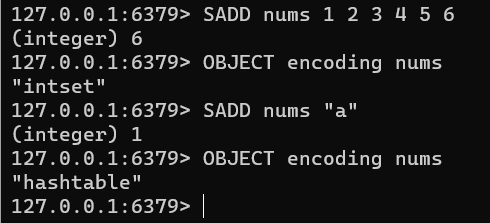
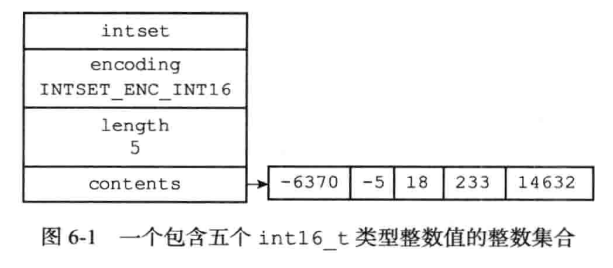
2.4.1 整数集合IntSet
1 | |
encoding有多种编码:INTSET_ENC_INT16、INTSET_ENC_INT32等,区别在于int字节数不同,表示的数的范围也不同。
2.4.2 IntSet扩容
IntSet扩容和普通数组扩容有一点区别,区别在于编码。
例如有一个IntSet有INT16整数1,2,3,现在需要往里面添加一个INT32整数65535。就与IntSet的encoding不符合了,需要进行升级(将所有INT16的整数升级为INT32)。
步骤如下:
- 计算所需的位数。原来占用的位数:
16*3 = 48位,都升级为INT32后占用的位数:32*4 = 128位,所以将数组空间开辟至128位。 - 除新分配空间(96-127位)外,从后往前依次将原来的整数升级为
INT32 - 在96-127位间添加
65535。 encoding也修改为INTSET_ENC_INT32
因为需要对每个元素都进行提升移位,所以IntSet添加新元素的时间复杂度为O(n)
升级前后对比图如下:
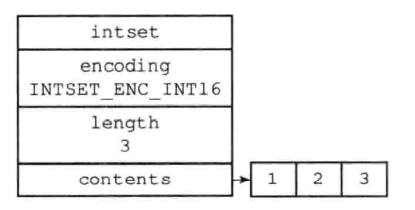

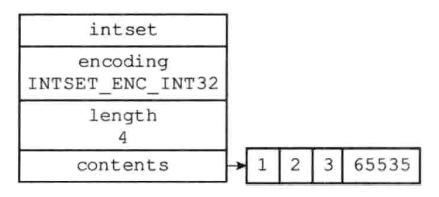
类型的自动提升可以非常灵活地保存数据,并且可以减少不必要的内存浪费。
注意的是IntSet只支持升级,不支持降级,一旦升级以后就会至少保持当前状态。
2.5 Sorted Set(ZSet)
ZSet是Redis中的有序集合。它的实现也有两种数据结构:压缩列表ziplist和跳表skiplist,可以看到
当zset中的元素数量大于最大值128或所有元素长度大于64字节时,会使用跳表skiplist作为底层实现,否则使用压缩列表ziplist实现。
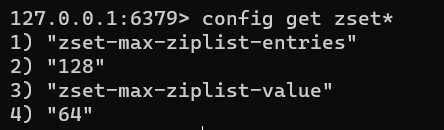
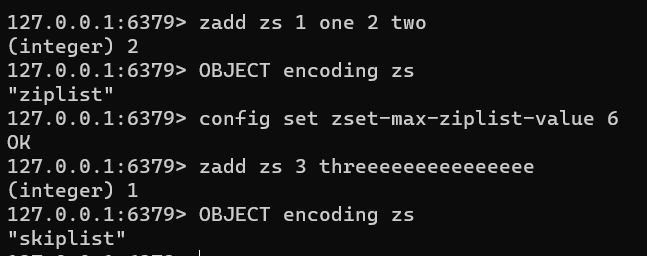
下面演示为了显示效果,将第二项配置改为6个字节。
2.5.1 压缩列表 ZipList
压缩列表时Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。

zlbytes[4 字节]:压缩列表占用字节数。zltail[4 字节]: 表尾节点距离起始地址有多少字节,无需遍历即可确定表尾地址。zllen[2 字节]:包含的节点数量。entry[不定]: 节点Entryzlend[1 字节]:标记压缩列表末端。
如下压缩列表:

表示这个压缩列表包含5个节点(0x5)总长210字节(0xd2),从起始地址p后移179字节(0xb3)就可以到达最后一个元素。
一个直观的图表示压缩列表如下:

下面是Entry的结构:

其中第一项previous_entry_length表示前一个entry的长度。所以用当前地址减去第一项即可得到前一项的地址,实现从后往前遍历。
- 如果前一节点的长度
小于254字节,那么previous_entry_length属性需要用1字节长的空间来保存这个长度值。 - 如果前一节点的长度
大于等于254字节,那么previous_entry_length属性需要用5字节长的空间来保存这个长度值。
一个存储"hello world"的Entry结构如下:

每个Entry可以保存一个字节数组或一个整数值。
1 | |
需要注意的是,因为当前Entry存储了前一Entry的长度,所以如果前面的Entry内容改变(增删改)导致所占字节数改变,而previous_entry_length都需要扩展到5字节,那么会引起后面的Entry全部进行更新,也称连锁更新。最坏情况下需要进行N次更新,每次空间重分配的最坏时间复杂度为O(n),所以连锁更新最坏复杂度为O(n^2)。
虽然最坏复杂度为O(n^2),但是造成性能问题的几率是比较低的,要同时满足下面的条件才会全部连锁
更新:
- 恰好有多个连续的、长度介于
250-253字节的节点,连锁更新才有可能被引发,实际情况中并不多见。 - 即使出现连锁更新,但只要被更新的节点不多,也不会对性能造成很大的影响。
所以ziplistpush等命令的平均时间复杂度为O(n),可以放心使用。
因为我们发现压缩列表相比普通的数组或列表,既节省内存、减少内存碎片的产生又方便,所以也可以将其作为哈希表的底层实现。
所以ZSet的实现只需要在zipList基础上进行排序去重即可。
但ZipList也有缺点:
- 元素过多时查询效率会非常低,因为是遍历进行查找。
- 新增或修改时,需要重新分配空间,有可能引发连锁更新。
所以ZipList只作为数据量小时的一种很好的替代方案。数据量大的时候就需要用到跳表SkipList
2.5.2 跳表 SkipList
跳跃表( skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
跳表定义如下:
1 | |
特性:
1、由很多层结构组成;
2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
3、最底层的链表包含了所有的元素;
4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
对照图理解更直观:
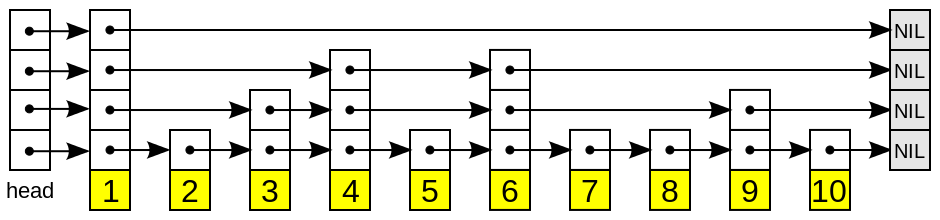

跳表的思想类似二分法和多级索引,下一层的节点都比上一层多(非二分之一),查询非常快且有序。
例如上图查找数字9。首先从第一层1开始,9>1,向右走一步,到达7,7<9,而右边节点为14,所以可以肯定在7-14之间的下面某一层。于是向下寻找,第二层右边节点为11>9,同理也在7-11下面某层之间,于是第三层向右一次找到9。如果顺序遍历,需要遍历节点5次才能找到9,使用跳表只需要遍历2次。
2.5.3跳表的时间复杂度和空间复杂度
假设单链表有n个节点。最下面一层作为第一层,每2个节点往上一层提取一个节点,那么第二层有\(\dfrac{n}{2}\)个,第k层有\(\dfrac{n}{(2^k-1)}\)个,最上面一层最少只有2个节点,可以得到跳表高度\(h = log_2n\)。
每一层遍历会发现不会超过3个节点。
所以可以得到跳表查询的时间复杂度为:\(O(log_n)\),媲美二分查找。
对于跳表的空间复杂度,可以得到总共所需的节点数= \(n +\dfrac{n}{2} + \dfrac{n}{4} + \dfrac{n}{8} + ··· \approx(2n)\)
所以跳表的空间复杂度为:\(O(n)\)
跳表不仅支持查询,而且还支持\(O(log_n)\)级别的插入和删除操作。性能媲美红黑树。
类似红黑树,二叉平衡树是通过左右旋来保持左右子树的大小平衡,而跳表是借助随机函数来更新索引结构。
通过一个随机函数来决定,比如通过 随机函数得到某个值 K, 那么就将这个节点添加到第二层到第K层节点中,避免出现极端情况退化为单链表。
相比红黑树,跳表也更善于进行区间查询,查询到节点后只需要顺序输出即可,类似B+树作为数据库区间查询的过程,而且比红黑树更容易实现。
总之,跳表有着二分查找的性能,红黑树的插入删除效率,和B+树的区间查询效率,且简单灵活,非常强大。
跳表的缺点我认为就是使用了一些冗余的节点来表示同一个元素,不过影响也不大。
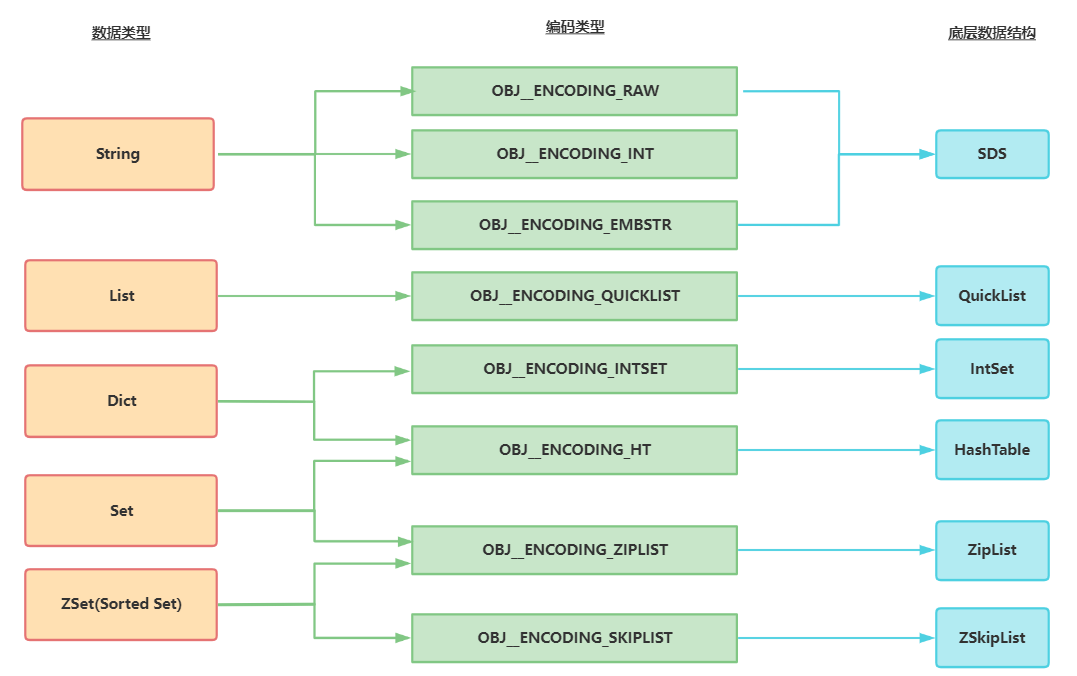
三、数据结构关系总结
五种数据结构及其底层数据结构关系图如下所示,编码类型即OBJECT ENCODING的值。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!