基于RISC-V架构和Rust编写自己的操作系统(一)
本文来自rCoreOs和自己实践的笔记。本部分内容包括搭建开发环境、编写简单内核、实现打印HelloWorld和错误处理。
RISC-V
一、ISA介绍


二、RISC-V
RISC-V念作“risk-five”,代表着Berkeley 所研发的第五代精简指令集。
X86:太复杂,IP问题
ARM:一样复杂,而且在2010年前还不支持64位,以及同样的IP问题。


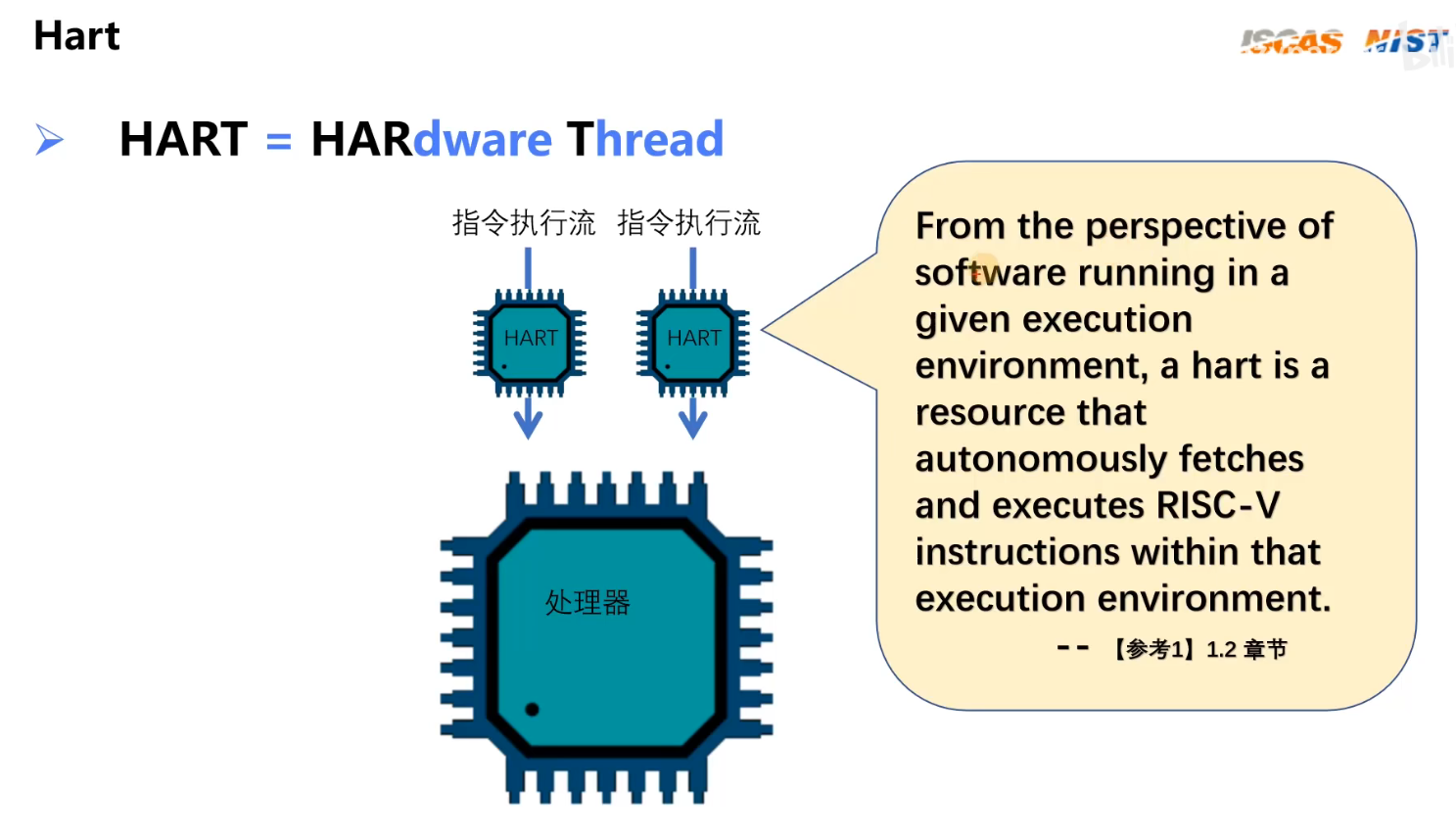
1.1 Hart
Hart:硬件线程,可以看作是一个独立运行的虚拟CPU,用于CPU并行执行任务。
因此RISC-V只关注Hart,不关注CPU。
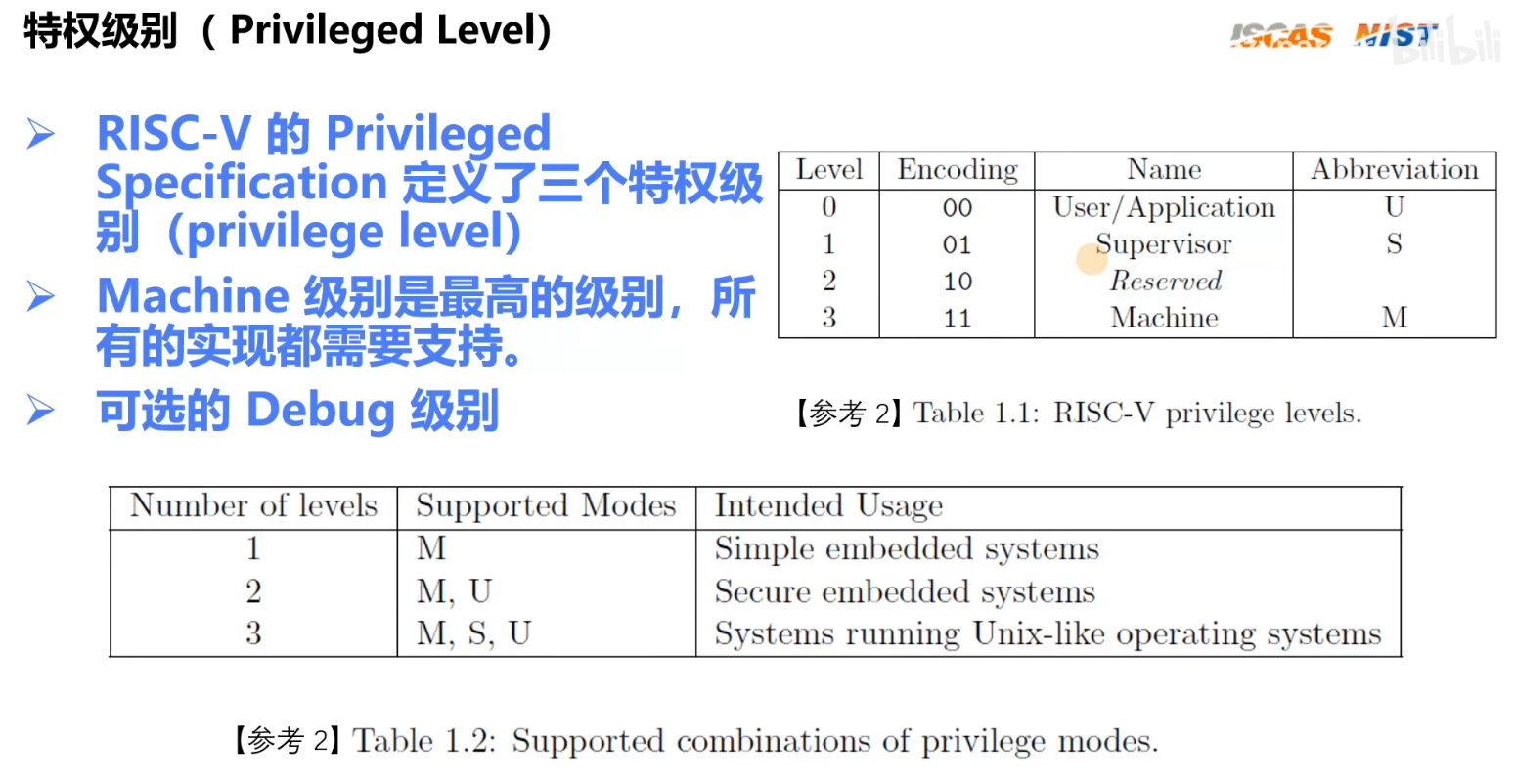
1.2 特权级别
类似Linux内核态-S、用户态-U。而Machine态如x86的保护模式和实模式。机器刚启动时是进入实模式,此时访问的地址都是物理地址,虚拟地址不生效。等启动到某个阶段,会开启保护模型,此时会启动MMU,然后虚拟地址再起作用。
不同态的主要区别就在于某些寄存器只能在特点状态下才能访问,这样就起到保护作用了。

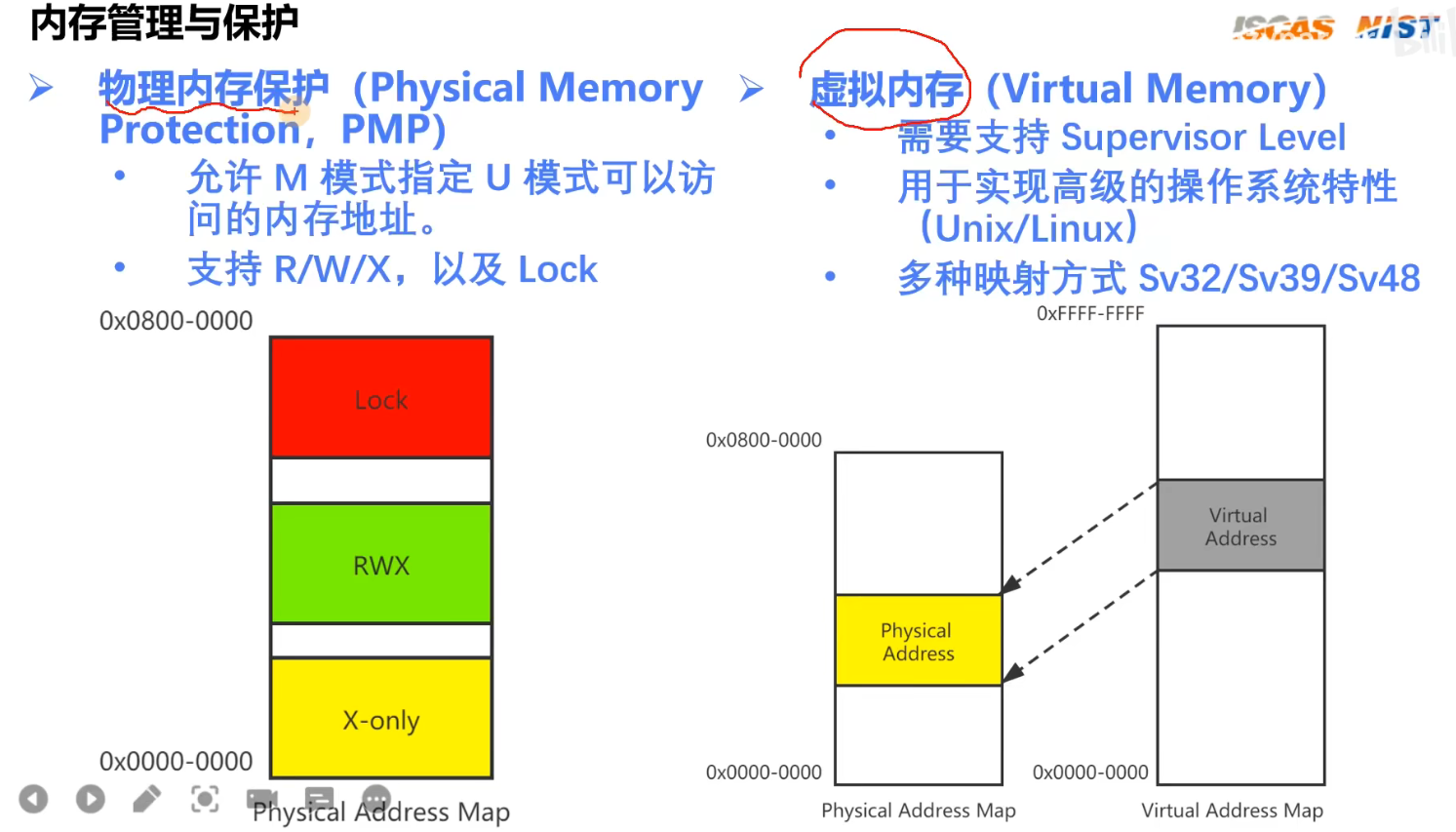
1.3 内存管理与保护
三、概述
多道批处理操作系统为此采用了多道程序设计技术,就是指允许同时把多个程序放入内存,并允许它们交替在 CPU 中运行,它们共享系统中的各种硬、软件资源。当一道程序因 I/O 请求而暂停运行时, CPU 便立即转去运行另一道程序。
3.1 概念介绍
3.1.1 RustSBI
RustSBI是RISC-V Supervisor Binary Interface 规范的缩写
SBI可以理解为一个内核运行环境,它可以引导启动内核、提供操作系统需要的接口等。
RISC-V标准中,“SBI”意味着“操作系统二进制接口”,运行在其上的操作系统会通过环境调用“ecall”指令,陷入到二进制接口的实现中,由其调用具体硬件的实现功能。
RustSBI由几个功能模块组成。SBI的初始化完成后,将进入引导启动模块,启动操作系统内核。还有兼容性模块能完成硬件到硬件间的支持,能模拟旧版硬件不存在的指令、寄存器,进一步延长操作系统的生命周期。
3.1.2 SBI和BIOS的关系
SBI 是 RISC-V Supervisor Binary Interface 规范的缩写,OpenSBI 是RISC-V官方用C语言开发的SBI参考实现;RustSBI 是用Rust语言实现的SBI。
BIOS 是 Basic Input/Output System,作用是引导计算机系统的启动以及硬件测试,并向OS提供硬件抽象层。
机器上电之后,会从ROM中读取引导代码,引导整个计算机软硬件系统的启动。而整个启动过程是分为多个阶段的,现行通用的多阶段引导模型为:
ROM -> LOADER -> RUNTIME -> BOOTLOADER -> OS
Loader 要干的事情,就是内存初始化,以及加载 Runtime 和 BootLoader 程序。而Loader自己也是一段程序,常见的Loader就包括 BIOS 和 UEFI,后者是前者的继任者。
Runtime 固件程序是为了提供运行时服务(runtime services),它是对硬件最基础的抽象,对OS提供服务,当我们要在同一套硬件系统中运行不同的操作系统,或者做硬件级别的虚拟化时,就离不开Runtime服务的支持。SBI就是RISC-V架构的Runtime规范。
BootLoader 要干的事情包括文件系统引导、网卡引导、操作系统启动配置项设置、操作系统加载等等。常见的 BootLoader 包括GRUB,U-Boot,LinuxBoot等。
而 BIOS/UEFI 的大多数实现,都是 Loader、Runtime、BootLoader 三合一的,所以不能粗暴的认为 SBI 跟 BIOS/UEFI 有直接的可比性。
如果把BIOS当做一个泛化的术语使用,而不是指某个具体实现的话,那么可以认为 SBI 是 BIOS 的组成部分之一。
四、应用程序和基本执行环境
4.1 移除rust标准库
因为RustStd标准库很多操作都依赖操作系统的系统调用,而我们在riscv上没有操作系统提供系统调用,所以需要移除Rust的标准库。
1 | |
由于移除了std,也没有panic!,一个简易的panic!替代程序如下:
1 | |
编译发现可以通过。
编译能通过说明生成了二进制。使用catgo install cargo-binutils和rustup component add llvm-tools-preview查看生成的文件。
$ file target/riscv64gc-unknown-none-elf/debug/hello

可以看到使用了risc-v。
1 | |
通过 file 工具对二进制程序 os
的分析可以看到它好像是一个合法的 RISC-V 64 可执行程序,但通过
rust-readobj 工具进一步分析,发现它的入口地址 Entry 是
0 ,从 C/C++ 等语言中得来的经验告诉我们, 0
一般表示 NULL 或空指针,因此等于 0
的入口地址看上去无法对应到任何指令。再通过 rust-objdump
工具把它反汇编,可以看到没有生成汇编代码。
所以,我们可以断定,这个二进制程序虽然合法,但它是一个空程序。
但是为什么没有生成汇编代码呢? 回想使用rust
std,即使运行一个空的main函数,都会生成很长一段汇编代码,进行各种系统调用,是因为
rust
标准库为了保证各个平台兼容性,即使用不到,也会生成一些冗余代码。而我们移除了std,程序也没有任何代码,所以也就不会生成汇编代码。
4.2 内核第一条指令(原理)
从 CPU
的视角看来,可以将物理内存看成一个大字节数组,而物理地址则对应于一个能够用来访问数组中某个元素的下标。该下标通常不以
0 开头,而通常以一个常数,如 0x80000000 开头。简言之,CPU
可以通过物理地址来寻址,并 逐字节
地访问物理内存中保存的数据。
当 CPU 以多个字节(比如 2/4/8 或更多)为单位访问物理内存(事实上并不局限于物理内存,也包括I/O外设的数据空间)中的数据时,就有可能会引入端序(也称字节顺序)和内存地址对齐的问题。即大端读取和小端读取问题。常见的 x86、RISC-V 等架构采用的是小端序(低位放低位,高位放高位)。
CPU 访问内存是通过数据总线(决定了每次读取的数据位数)和地址总线(决定了寻址范围)来进行的,基于计算机的物理组成和性能需求,CPU 一般会要求访问内存数据的首地址的值为 4 或 8 的整数倍。
对于 RISC-V 处理器而言,load/store 指令进行数据访存时,数据在内存中的地址应该对齐。如果访存 32 位数据,内存地址应当按 32 位(4字节)对齐。如果数据的地址没有对齐,执行访存操作将产生异常。这也是在学习内核编程中经常碰到的一种 bug。
4.2.1 Qemu模拟器
由于我们的电脑环境都是x86或arm架构的,无法运行riscv的指令集。所以需要Qemu模拟器模拟riscv环境执行riscv程序。我们编写的内核将主要在 Qemu 模拟器上运行来检验其正确性。
我们使用软件 qemu-system-riscv64 来模拟一台 64 位 RISC-V
架构的计算机,它包含一个 CPU 、一条物理内存以及若干 I/O 外设。
1 | |
-machine virt表示将模拟的 64 位 RISC-V 计算机设置为名为virt的虚拟计算机。我们知道,即使同属同一种指令集架构,也会有很多种不同的计算机配置,比如 CPU 的生产厂商和型号不同,支持的 I/O 外设种类也不同。关于virt平台的更多信息可以参考 1 。Qemu 还支持模拟其他 RISC-V 计算机,其中包括由 SiFive 公司生产的著名的 HiFive Unleashed 开发板。-nographic表示模拟器不需要提供图形界面,而只需要对外输出字符流。- 通过
-bios可以设置 Qemu 模拟器开机时用来初始化的引导加载程序(bootloader),这里我们使用预编译好的rustsbi-qemu.bin,它需要被放在与os同级的bootloader目录下,该目录可以从每一章的代码分支中获得。 - 通过虚拟设备
-device中的loader属性可以在 Qemu 模拟器开机之前将一个宿主机上的文件载入到 Qemu 的物理内存的指定位置中,file和addr属性分别可以设置待载入文件的路径以及将文件载入到的 Qemu 物理内存上的物理地址。注意这里我们载入的文件带有.bin后缀,它并不是上一节中我们移除标准库依赖后构建得到的内核可执行文件,而是还要进行加工处理得到内核镜像。我们后面再进行深入讨论。
4.2.2 Qemu启动流程
virt 平台上,物理内存的起始物理地址为
0x80000000 ,物理内存的默认大小为 128MiB ,它可以通过
-m 选项进行配置。在本书中,我们只会用到最低的 8MiB
物理内存,对应的物理地址区间为 [0x80000000,0x80800000)
。如果使用上面给出的命令启动 Qemu ,那么在 Qemu
开始执行任何指令之前,首先两个文件将被加载到 Qemu 的物理内存中:即作为
bootloader 的 rustsbi-qemu.bin 被加载到物理内存以物理地址
0x80000000 开头的区域上,同时内核镜像 os.bin
被加载到以物理地址 0x80200000 开头的区域上。
为什么加载到这两个位置呢?这与 Qemu 模拟计算机加电启动后的运行流程有关。一般来说,计算机加电之后的启动流程可以分成若干个阶段,每个阶段均由一层软件负责,每一层软件的功能是进行它应当承担的初始化工作,并在此之后跳转到下一层软件的入口地址,也就是将计算机的控制权移交给了下一层软件。Qemu 模拟的启动流程则可以分为三个阶段:第一个阶段由固化在 Qemu 内的一小段汇编程序负责;第二个阶段由 bootloader 负责;第三个阶段则由内核镜像负责。
- 第一阶段:将必要的文件载入到 Qemu 物理内存之后,Qemu CPU
的程序计数器(PC, Program Counter)会被初始化为
0x1000,因此 Qemu 实际执行的第一条指令位于物理地址0x1000,接下来它将执行寥寥数条指令并跳转到物理地址0x80000000对应的指令处并进入第二阶段。从后面的调试过程可以看出,该地址0x80000000被固化在 Qemu 中,作为 Qemu 的使用者,我们在不触及 Qemu 源代码的情况下无法进行更改。 - 第二阶段:由于 Qemu 的第一阶段固定跳转到
0x80000000,我们需要将负责第二阶段的 bootloaderrustsbi-qemu.bin放在以物理地址0x80000000开头的物理内存中,这样就能保证0x80000000处正好保存 bootloader 的第一条指令。在这一阶段,bootloader 负责对计算机进行一些初始化工作,并跳转到下一阶段软件的入口,在 Qemu 上即可实现将计算机控制权移交给我们的内核镜像os.bin。这里需要注意的是,对于不同的 bootloader 而言,下一阶段软件的入口不一定相同,而且获取这一信息的方式和时间点也不同:入口地址可能是一个预先约定好的固定的值,也有可能是在 bootloader 运行期间才动态获取到的值。我们选用的 RustSBI 则是将下一阶段的入口地址预先约定为固定的0x80200000,在 RustSBI 的初始化工作完成之后,它会跳转到该地址并将计算机控制权移交给下一阶段的软件——也即我们的内核镜像。 - 第三阶段:为了正确地和上一阶段的 RustSBI
对接,我们需要保证内核的第一条指令位于物理地址
0x80200000处。为此,我们需要将内核镜像预先加载到 Qemu 物理内存以地址0x80200000开头的区域上。一旦 CPU 开始执行内核的第一条指令,证明计算机的控制权已经被移交给我们的内核,也就达到了本节的目标。
总结:1、Qemu开辟内存物理地址,加载最初始的文件。
2、从0x80000000开始执行bios的内容,所以需要将bootloader内容放在这个地址。
3、 执行完bios,从0x80200000开始初始化内核镜像。
真实计算机的启动流程大致上也可以分为三个阶段:
- 第一阶段:加电后 CPU 的 PC 寄存器被设置为计算机内部只读存储器(ROM,Read-only Memory)的物理地址,随后 CPU 开始运行 ROM 内的软件。我们一般将该软件称为固件(Firmware),它的功能是对 CPU 进行一些初始化操作,将后续阶段的 bootloader 的代码、数据从硬盘载入到物理内存,最后跳转到适当的地址将计算机控制权转移给 bootloader 。
- 第二阶段:bootloader 同样完成一些 CPU 的初始化工作,将操作系统镜像从硬盘加载到物理内存中,最后跳转到适当地址将控制权转移给操作系统。可以看到一般情况下 bootloader 需要完成一些数据加载工作,这也就是它名字中 loader 的来源。
- 第三阶段:控制权被转移给操作系统。由于篇幅所限后面我们就不再赘述了。
值得一提的是,为了让计算机的启动更加灵活,bootloader 目前可能非常复杂:它可能也分为多个阶段,并且能管理一些硬件资源,从复杂性上它已接近一个传统意义上的操作系统。
4.2.3 编译流程
从源代码得到可执行文件的编译流程可被细化为多个阶段(虽然输入一条命令便可将它们全部完成):
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
在此期间链接器主要完成两件事情:
- 第一件事情是将来自不同目标文件的段在目标内存布局中重新排布。如下图所示,在链接过程中,分别来自于目标文件
1.o和2.o段被按照段的功能进行分类,相同功能的段被排在一起放在拼装后的目标文件output.o中。注意到,目标文件1.o和2.o的内存布局是存在冲突的,同一个地址在不同的内存布局中存放不同的内容。而在合并后的内存布局中,这些冲突被消除。
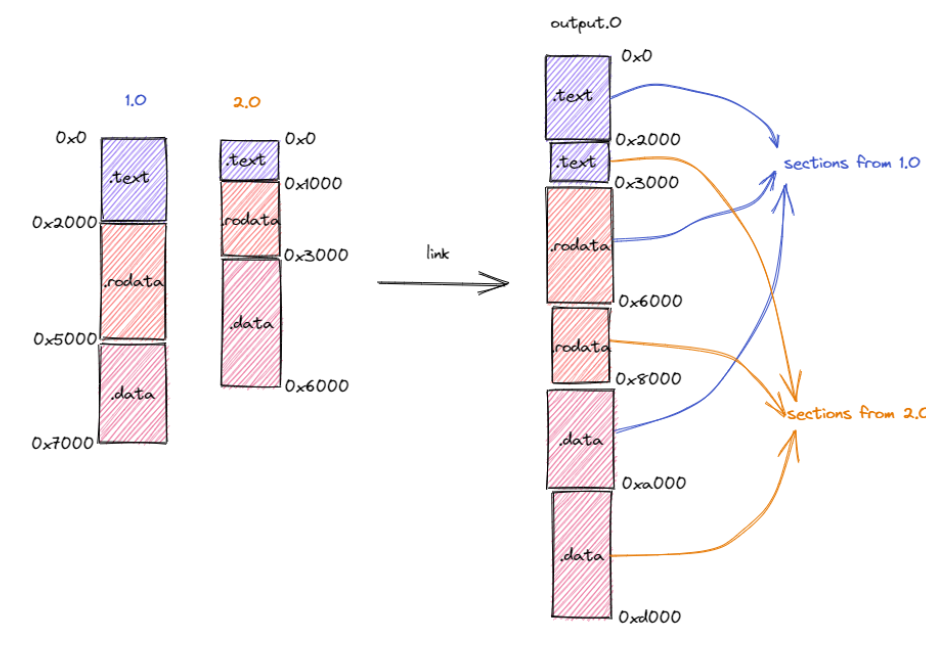
第二件事情是将符号替换为具体地址。(公开的全局变量、函数)。取决于符号来自于模块内部还是其他模块,我们还可以进一步将符号分成内部符号和外部符号。然而,在机器码级别(也即在目标文件或可执行文件中)我们并不是通过符号来找到索引我们想要访问的变量或函数,而是直接通过变量或函数的地址。例如,如果想调用一个函数,那么在指令的机器码中我们可以找到函数入口的绝对地址或者相对于当前 PC 的相对地址。
那么,符号何时被替换为具体地址呢?因为符号对应的变量或函数都是放在某个段里面的固定位置(如全局变量往往放在
.bss或者.data段中,而函数则放在.text段中),所以我们需要等待符号所在的段确定了它们在内存布局中的位置之后才能知道它们确切的地址。当一个模块被转化为目标文件之后,它的内部符号就已经在目标文件中被转化为具体的地址了,因为目标文件给出了模块的内存布局,也就意味着模块内的各个段的位置已经被确定了。然而,此时模块所用到的外部符号的地址无法确定。我们需要将这些外部符号记录下来,放在目标文件一个名为符号表(Symbol table)的区域内。由于后续可能还需要重定位,内部符号也同样需要被记录在符号表中。外部符号需要等到链接的时候才能被转化为具体地址。假设模块 1 用到了模块 2 提供的内容,当两个模块的目标文件链接到一起的时候,它们的内存布局会被合并,也就意味着两个模块的各个段的位置均被确定下来。此时,模块 1 用到的来自模块 2 的外部符号可以被转化为具体地址。同时我们还需要注意:两个模块的段在合并后的内存布局中被重新排布,其最终的位置有可能和它们在模块自身的局部内存布局中的位置相比已经发生了变化。因此,每个模块的内部符号的地址也有可能会发生变化,我们也需要进行修正。上面的过程被称为重定位(Relocation),这个过程形象一些来说很像拼图:由于模块 1 用到了模块 2 的内容,因此二者分别相当于一块凹进和凸出一部分的拼图,正因如此我们可以将它们无缝地拼接到一起。
4.3 内核第一条指令(实践)
1 | |
1 | |
通过 include_str! 宏将同目录下的汇编代码
entry.asm 转化为字符串并通过 global_asm!
宏嵌入到代码中。global_asm! 宏已被加入到 Rust 核心库 core
中。
之前原理说过,需要调整我们的内存地址布局,链接器默认的布局不符合要求,所以需要通过 链接脚本 (Linker Script) 调整链接器来与Qemu正确对接。
4.3.1 调整内存布局
修改config,使用我们自己的链接脚本src/linker.ld.
1 | |
链接脚本如下:
1 | |
最终的合并结果是,在最终可执行文件中各个常见的段
.text, .rodata .data, .bss
从低地址到高地址按顺序放置,每个段里面都包括了所有输入目标文件的同名段,且每个段都有两个全局符号给出了它的开始和结束地址(比如
.text 段的开始和结束地址分别是 stext 和
etext )。
接下来通过cargo build --release生成内核可执行文件:

通过file查看生成的文件属性,是一个运行在 64 位 RISC-V
架构计算机上的可执行文件,它是静态链接得到的。
0x80200000可不可以换成其他的值?假设
0x80200111是一个函数的入口地址,如果一条位于0x80200111指令会调用该函数,那么这条指令也不一定要用到绝对地址0x80201111,而是用函数入口地址相对于当前指令地址0x80200111的相对地址0x1000。这种程序被称为 位置无关可执行文件(PIE,Position-independent Executable),初始地址可以为任意值,基于相对地址进行定位即可。而我们的内核不是位置无关的,必须有一个确定的内存布局,且加载到该位置才可以正常运行,所以起始地址固定为
0x80200000.
Qemu不支持动态链接,所以内核都是采用静态链接的方式进行编译。
4.3.2 手动加载内核可执行文件
刚刚编译得到的可执行文件符合内存布局要求,但不能直接提交给Qemu。因为还有一些多余的元数据信息。
如下图左边的Metadata0即元数据,加载到Qemu后,在BASE_ADDR内核开始地址找不到下图的浅蓝色的第一条内核指令,而又无法识别元数据。所以需要手动将元数据进行丢弃。
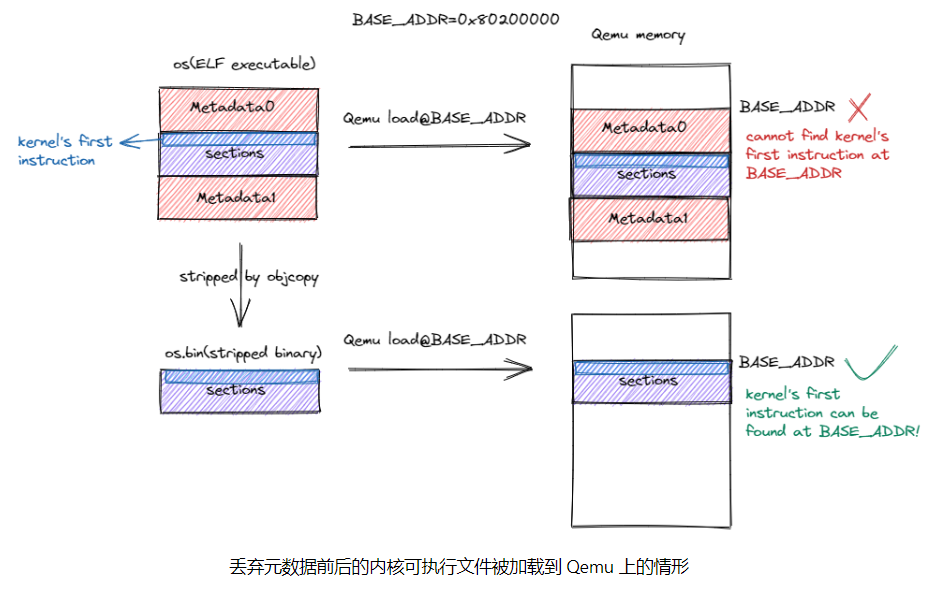
使用如下命令可以丢弃内核可执行文件中的元数据得到内核镜像:
1 | |
可以使用 stat
工具来比较内核可执行文件和内核镜像的大小:
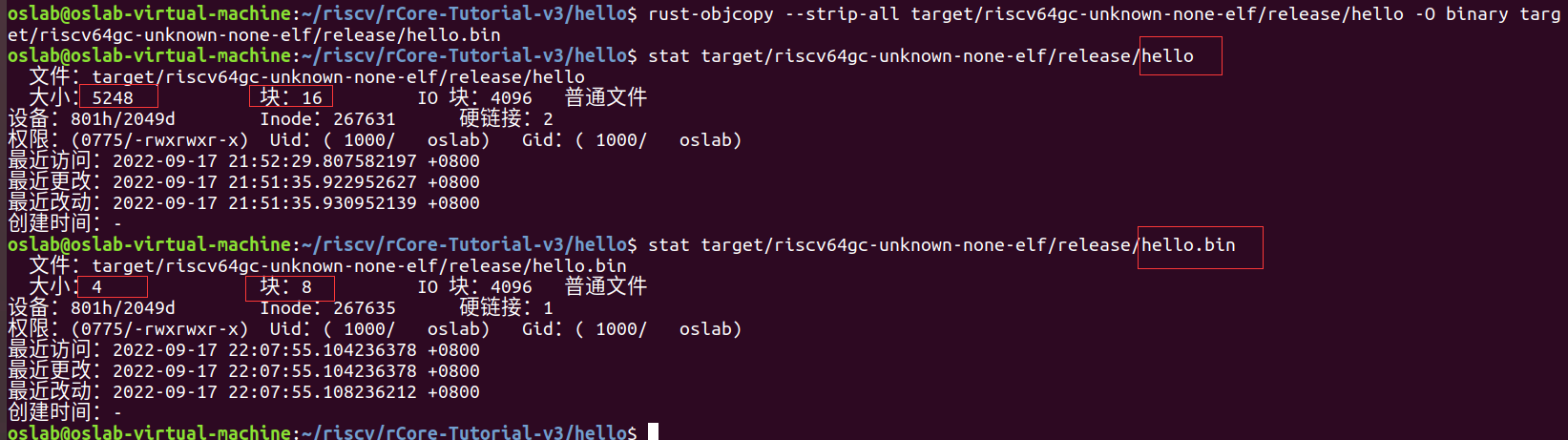
内核镜像只有4字节大小,因为这里面只包含我们在entry.asm中编写的第一条指令。一般情况下
RISC-V 架构的一条指令位宽即为 4 字节。
元数据有5244字节,其实元数据是有用的,可以帮我们更加灵活地加载并使用可执行文件,比如加载时完成一些重定向和动态链接等。由于Qemu加载功能过于简单,所以我们手动进行加载。
4.3.3 基于GDB的验证启动流程
使用如下命令启动Qemu并加载RUSTSBI和内核镜像:
1 | |
-s:让Qemu监听TCP1234端口等待GDB客户端连接
-S:让Qemu收到GDB请求后再开始运行
打开另一个终端,启动一个 GDB 客户端连接到 Qemu :
1 | |
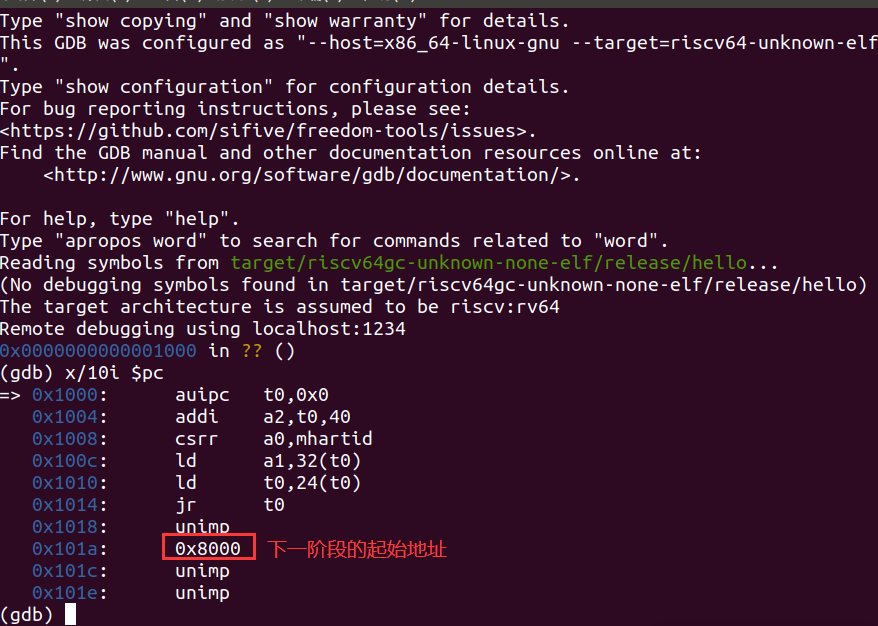
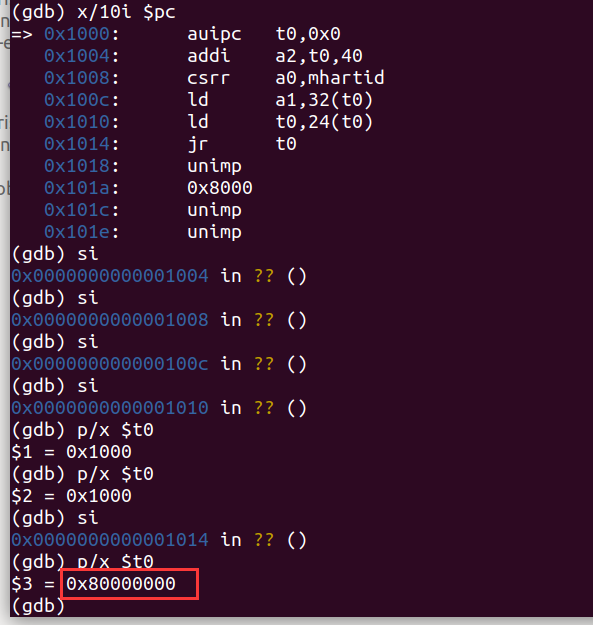
使用x/10i $pc从当前 PC 值的位置开始,在内存中反汇编 10
条指令
不过可以看到 Qemu 的固件仅包含 5 条指令,从 0x1014
开始都是数据,当数据为 0 的时候则会被反汇编为 unimp 指令。
0x101a 处的数据 0x8000 是能够跳转到
0x80000000
进入启动下一阶段的关键。有兴趣的读者可以自行探究位于 0x1000
和 0x100c 两条指令的含义。总之,在执行位于
0x1010 的指令之前,寄存器 t0 的值恰好为
0x80000000 ,随后通过 jr t0
便可以跳转到该地址。
通过单步调试si可以看到,
p/x %t0是以16进制打印t0的值。当0x1010执行完后,0x80000000即RUSTSBI的入口,控制权就会转交给RUSTSBI。
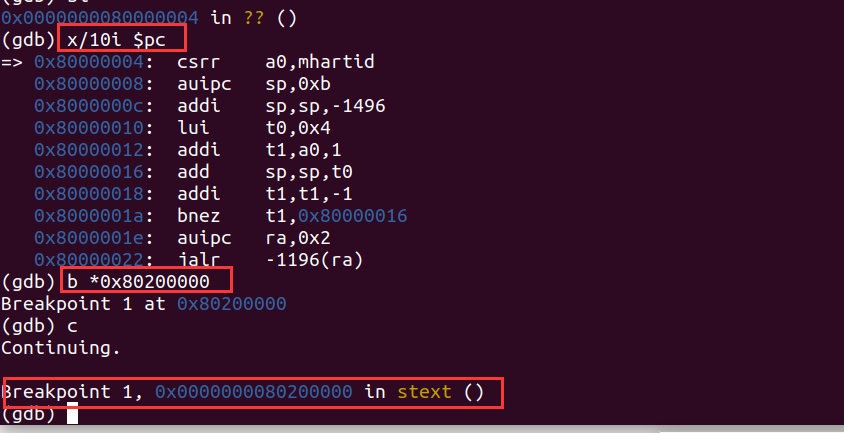
我们继续单步调试,进入RUSTSBI,使用x/10i $pc查看RUSTSBI反汇编的前10条指令。使用b *0x80200000在0x80200000处打一个断点,看看程序能否走到我们的内核起始地址。然后使用c继续运行,可以看到成功在0x80200000停了下来。
然后我们可以看看内核的反汇编代码,和我们写的entry.asm进行对比。使用x/5i $pc查看pc位置处后面5条指令,可以看到第一条内核指令和我们entry.asm中编写的指令符合。
1 | |
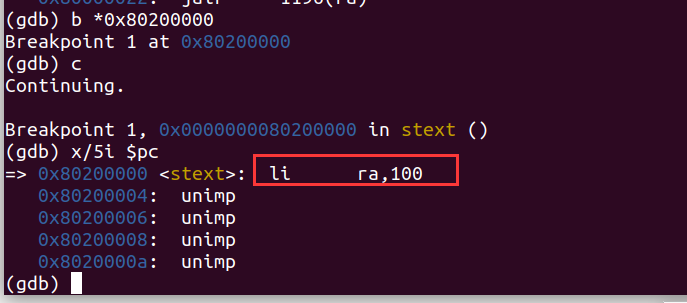
这里ra是x1的别名,可以使用p/d $x1以10进制打印x1寄存器的值。
1 | |
p/x $sp可以查看栈指针sp的值,现在为0,我们会设置好栈指针使得内核代码可以正常进行函数调用。
4.4 为内核支持函数调用
虽然我们在Qemu上执行了内核的第一条我们手动编写的汇编指令,但是我们是使用Rust编写内核,而不是汇编。所以我们需要将控制权转交给Rust编写的内核入口。
所以我们在汇编中指定栈地址来调用Rust的函数。
4.4.1 函数调用的地址跳转
在调用函数时,我们知道需要保存当前pc寄存器的值,方便在函数调用完毕后返回到原来的地址继续执行。
RISC-V以下两条指令用于指令跳转。

rs 表示 源寄存器 (Source Register), imm 表示 立即数 (Immediate),是一个常数,二者构成了指令的输入部分;而 rd 表示 目标寄存器 (Destination Register),它是指令的输出部分。
假设所有指令长度都为4字节。
则rd <- pc + 4的意思是:将pc寄存器当前下一条指令地址保存到目标寄存器(通常为ra(x1)寄存器),所以返回时只需要返回ra寄存器的值即可(即ret伪指令)。
pc <- rs + imm表示将改变pc寄存器的值,表示在函数内部的移动。结束后会重置为ra之前保存的值。
在进行函数调用的时候,我们通过 jalr
指令保存返回地址并实现跳转;而在函数即将返回的时候,则通过
ret
伪指令回到跳转之前的下一条指令继续执行。这样,RISC-V
的这两条指令就实现了函数调用流程的核心机制。
以上情况对于单个函数调用可以应对,但是如果有函数嵌套呢?单个ra寄存器肯定不能全部保存完。
所以我们需要上下文context来保存函数调用前后的信息。
我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为 函数调用上下文 (Function Call Context) 。
每个CPU只有一套寄存器,所以要保持上下文不变,就需要物理内存的帮助。具体即在调用子函数前,在内存中保存上下文的寄存器,调用完毕后,恢复上下文的寄存器。
上下文寄存器被分为两类:
- 被调用者保存(Callee-Saved)寄存器:被调用的函数来保存可能会被覆盖的寄存器。
- 调用者保存(Caller-Saved)寄存器:调用的函数来保存可能会被覆盖的寄存器。
上下文保存具体过程:
- 调用函数:首先保存不希望在函数调用过程中发生变化的 调用者保存寄存器 ,然后通过 jal/jalr 指令调用子函数,返回之后恢复这些寄存器。
- 被调用函数:在被调用函数的起始,先保存函数执行过程中被用到的 被调用者保存寄存器 ,然后执行函数,最后在函数退出之前恢复这些寄存器。
我们发现无论是调用函数还是被调用函数,都会需要保存和恢复寄存器的汇编代码,可以分别将其称为 开场 (Prologue) 和 结尾 (Epilogue),它们会由编译器帮我们自动插入,来完成相关寄存器的保存与恢复。
区分被调用者保存(Callee-Saved)寄存器CS1和调用者保存(Caller-Saved)寄存器CS2的关键点在于,寄存器的值是谁保存的。
主函数调用子函数,主函数先备份寄存器的值,称为CS2。
主函数调用子函数,子函数先备份寄存器的值,执行结束后恢复,称为CS1
4.4.2 调用规范
调用规范 (Calling Convention) 约定在某个指令集架构上,某种编程语言的函数调用如何实现。它包括了以下内容:
- 函数的输入参数和返回值如何传递;
- 函数调用上下文中调用者/被调用者保存寄存器的划分;
- 其他的在函数调用流程中对于寄存器的使用方法。
RISC-V上C语言的调用规范的32通用寄存器规定如下:
| 寄存器组 | 保存者 | 功能 |
|---|---|---|
a0~a7( x10~x17 ) |
调用者保存 | 用来传递输入参数。其中的 a0 和 a1 还用来保存返回值。 |
t0~t6( x5~x7,x28~x31 ) |
调用者保存 | 作为临时寄存器使用,在被调函数中可以随意使用无需保存。 |
s0~s11( x8~x9,x18~x27 ) |
被调用者保存 | 作为临时寄存器使用,被调函数保存后才能在被调函数中使用。 |
剩下的 5 个通用寄存器情况如下:
- zero(
x0) 之前提到过,它恒为零,函数调用不会对它产生影响; - ra(
x1) 是调用者保存的,不过它并不会在每次调用子函数的时候都保存一次,而是在函数的开头和结尾保存/恢复即可。虽然ra看上去和其它被调用者保存寄存器保存的位置一样,但是它确实是调用者保存的。 - sp(
x2) 是被调用者保存的。这个是之后就会提到的栈指针 (Stack Pointer) 寄存器。 - fp(
s0),它既可作为s0临时寄存器,也可作为栈帧指针(Frame Pointer)寄存器,表示当前栈帧的起始位置,是一个被调用者保存寄存器。 - gp(
x3) 和 tp(x4) 在一个程序运行期间都不会变化,因此不必放在函数调用上下文中。它们的用途在后面的章节会提到。
4.4.3 栈
函数调用上下文的保存/恢复时机以及寄存器都是保存在栈中的。
sp 寄存器常用来保存 栈指针 (Stack
Pointer),它指向内存中栈顶地址。在 RISC-V
架构中,栈是从高地址向低地址增长的。
sp
是一个被调用者保存寄存器,因为函数的结尾会回收栈帧,恢复调用前的状态。
一个函数的栈的栈帧包含内容如下:
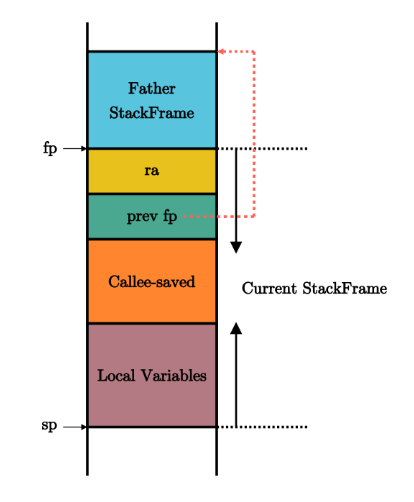
ra寄存器保存其返回之后的跳转地址,是一个调用者保存寄存器;- 父亲栈帧的结束地址
fp,是一个被调用者保存寄存器; - 其他被调用者保存寄存器
s1~s11; - 函数所使用到的局部变量。
通过fp指针指向的ra的值,可以组成一条完整的调用链,可以根据这个进行函数调用关系的跟踪。
接下来需要创建栈,但有几个问题需要考虑:
- 如何保证sp指向合法的物理内存?
- 如何保证在函数调用期间栈内容不断修改的情况下,sp指向的内存不与其他代码、数据段相交?
4.4.4 分配并使用栈
在entry.asm中分配栈空间,并将栈指针sp设置为栈顶,再将控制权交给Rust。
1 | |
linker.ld中显示了汇聚到.bss段中
1 | |
.bss
段一般放置需要被初始化为零的数据。但尝试将其放置到全局数据
.data 段中但最后未能成功,因此才决定将其放置到
.bss 段中。
全局符号 sbss 和 ebss 分别指向
.bss 段除 .bss.stack
以外的起始和终止地址,我们在使用这部分数据之前需要将它们初始化为零。
rust_main是我们定义的Rust内核函数的入口,也是第一个入栈的栈帧(内核运行全程最深的栈帧)。
1 | |
由于控制权已经转交给Rust,我们可以在main函数中做下一项初始化工作:清空.bss段。因为里面保存了全局变量等一些信息,我们每次运行时需要确保清空。
1 | |
第16行我们将
.bss段内的一个地址转化为一个 裸指针 (Raw Pointer),并将它指向的值修改为 0。这在 C 语言中是一种司空见惯的操作,但在 Rust 中我们需要将他包裹在 unsafe 块中。这是因为,Rust 认为对于裸指针的 解引用 (Dereference) 是一种 unsafe 行为。所以对于Rust语义约束之外的代码,我们都需要使用unsafe来标识,除了问题我们自己负责。因此出了问题后首先应先检查unsafe中的代码,这里面出错的机率更大。
到此我们顺利完成了函数调用栈空间的分配,可以将Rust中函数调用的过程存储到栈中了。
4.5 基于SBI服务完成输出与关机
Rust除了初始化工作,还会为内核提供响应。当内核发出请求时,计算机会转由 RustSBI 控制来响应内核的请求,待请求处理完毕后,计算机控制权会被交还给内核。
这个过程和函数调用比较像,但是内核无法通过函数调用来请求 RustSBI 提供的服务,这是因为内核并没有和 RustSBI 链接到一起,我们仅仅使用 RustSBI 构建后的可执行文件,因此内核对于 RustSBI 的符号一无所知。事实上,内核需要通过另一种复杂的方式来“调用” RustSBI 的服务。
我们将内核与 RustSBI
通信的相关功能实现放在sbi.rs中:
1 | |
which 表示请求 RustSBI 的服务的类型(RustSBI
可以提供多种不同类型的服务), arg0 ~ arg2
表示传递给 RustSBI 的 3 个参数,而 RustSBI
在将请求处理完毕后,会给内核一个返回值.。
我们定义一些入参的服务常量(which的值)。
1 | |
如字面意思,服务 SBI_CONSOLE_PUTCHAR
可以用来在屏幕上输出一个字符。我们将这个功能封装成
console_putchar 函数:
1 | |
类似的,还可以将关机服务 SBI_SHUTDOWN 封装成
shutdown 函数:
1 | |
4.5.1 实现格式化输出
console_putchar 的功能过于受限,如果想打印一行
Hello world! 的话需要进行多次调用。能否像本章第一节那样使用
println! 宏一行就完成输出呢?因此我们尝试自己编写基于
console_putchar 的 println! 宏。
1 | |
现在我们就可以使用println!()输出字符串到终端上了!
通过命令启动Qemu,可以发现在内核地址分配完成,控制权交给Rust后,打印出了Hello World。
1 | |

4.5.2 处理致命错误
Rust将错误分为可恢复错误和不可恢复错误。我们主要关注不可恢复错误,即报错后程序会自动停止。我们在lang_item.rs中之前写过一个panic函数。
1 | |
在目前的实现中,当遇到不可恢复错误的时候,被标记为语义项
#[panic_handler] 的 panic
函数将会被调用,然而其中只是一个死循环,会使得计算机卡在这里。借助前面实现的
println! 宏和 shutdown 函数,我们可以在
panic 函数中打印错误信息并关机:
1 | |
我们需要在 main.rs 开头加上
#![feature(panic_info_message)] 才能通过
PanicInfo::message 获取报错信息。
在main函数中添加panic!进行测试
1 | |
记得每次更新内核后需要使用cargo build --release重新编译生成可执行文件、并且去除掉元信息。
去除内核元信息:
1 | |
使用下面代码直接启动内核:
1 | |
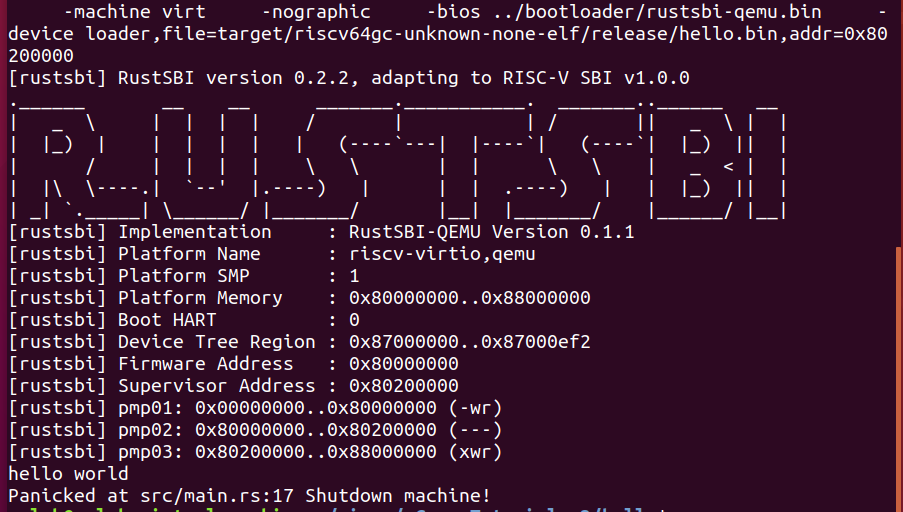
可以看到最后一行打印了报错的源代码和行数。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!