Redis学习笔记
Nosql概述
为什么要用Nosql
- Mysql单机时代
早期时代一个基本网站的访问量一般不会太大,单个数据库完全足够。
那个时候,更多的去使用静态网页Html ~服务器根本没有太大的压力!I 思考一下,这种情况下:整个网站的瓶颈是什么? 1、数据量如果太大、一个机器放不下了! 2、数据的索引( B+ Tree) , 一个机器内存也放不下 3、访问量(读写混合) , 一个服务器承受不了~
- Memcache缓存+Mysql+垂直拆分(读写分离)
网站80%的情况都是在读,每次都要去查询数据库的话就十分的麻烦!所以说我们希望减轻数据的压力,我们可以使用缓存来保证效率!
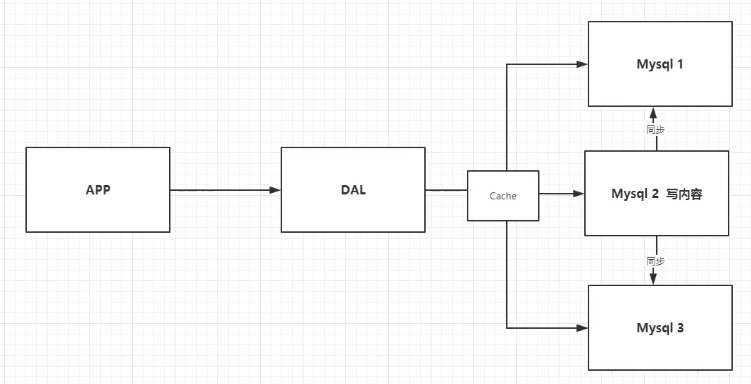
- 分库分表+水平拆分
技术和业务发展的同时,对人的要求也越来越高
早些年MyISAM:表锁,十分影响效率!高并发下就会出现严重的锁问题 转战Innodb :行锁 慢慢的就开始使用分库分表来解决写的压力! MySQL 在哪个年代推出了表分区!这个并没有多少公司使用! MySQL的集群,很好满足哪个年代的所有需求!
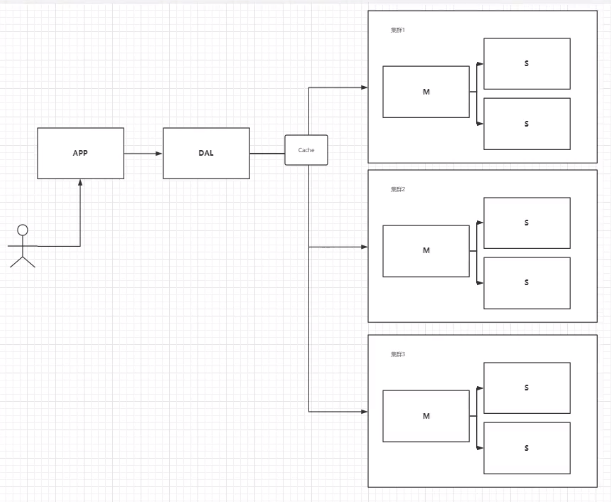
如今的年代
2010--2020十年之间,世界已经发生了翻天覆地的变化; (定位,也是一种数据,音乐,热榜! ) MySQL等关系型数据库就不够用了! 数据量很多,变化很快~ ! MySQL有的使用它来村粗- -些比较大的文件,博客,图片!数据库表很大,效率就低了!如果有一-种数据库来专[ ]处理这种数据, MySQL压力就变得十分小(研究如何处理这些问题! ) 大数据的10压力下,表几乎没法更大!
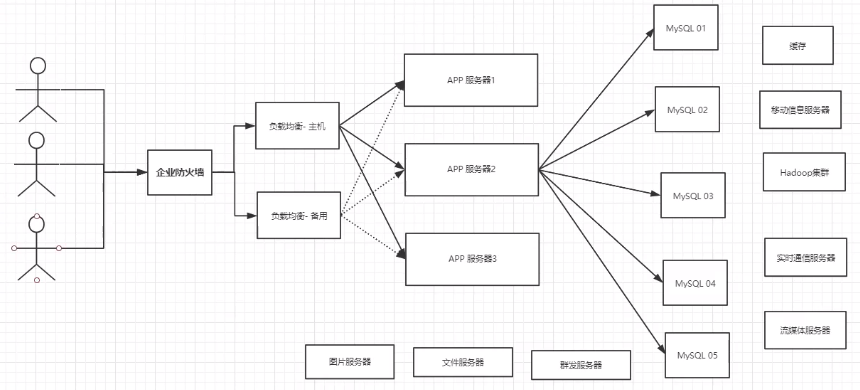
- 为什么要用Nosql
用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长! 这时候我们就需要使用NoSQL数据库的, Nosql可以很好的处理以上的情况!
什么是NoSQL
NoSQL:Not only SQL(不仅仅是SQL)
关系型数据库:表格,行, 列
NoSQL泛指非关系型数据库的,随着web2.0互联网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区!暴露出来很多难以克服的问题, NoSQL在当今大数据环境下发展的十分迅速, Redis是发展最快的,而且是我们当下必须要掌握的-一个技术!|
NoSQL特点
解耦! 1、方便扩展(数据之间没有关系,很好扩展! ) 2、大数据量高性能( Redis - -秒写8万次,读取11万, NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高! ) 3、数据类型是多样型的! (不需要事先设计数据库! 随取随用)
- 传统RDBMS和NoSQL
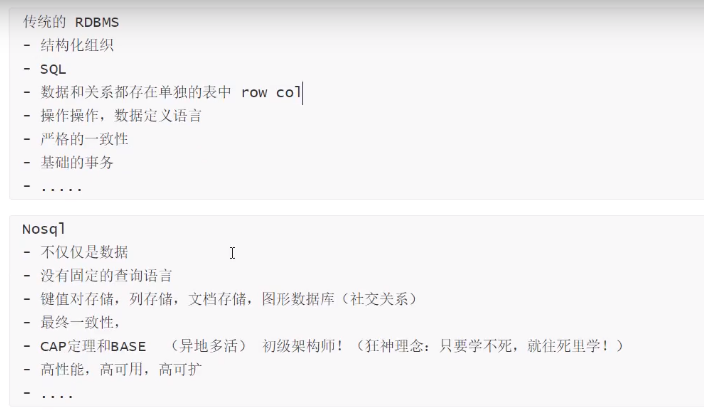
大数据时代的3V :主要是描述问题的 1.海量Volume 2.多样Variety 3.实时Velocity 大数据时代的3高:主要是对程序的要求 1.高并发 2.高可拓 3.高性能
真正在公司中的实践: NoSQL + RPBMS
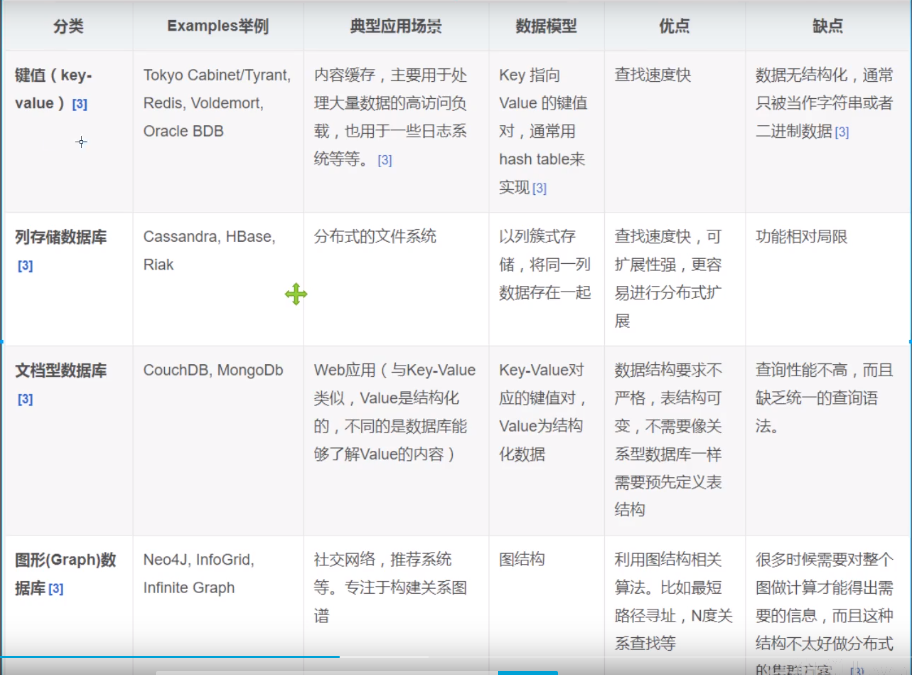
NoSQL四大分类
KV键值对
- 新浪:Redis
- 美团:Redis+Tair
- 阿里,百度:Redis+Memcache
文档型数据库(bson格式和json一样)
- MongoDB(一般必须掌握)
- 是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MongoDB是-个介于关系型数据库和非关系型数据中中间的产品!|是非关系型数据库中功能最丰富的,最像关系型数据库的.
- MongoDB(一般必须掌握)
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
- 存放关系,如朋友圈社交网络,广告推荐.
- Neo4j
四种类型对比
Redis概述
什么是Redis
Redis ( Remote Dictionary Server ),即远程字典服务! 是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库 ,并提供多种语言的APl。
- Redis能干什么
- 内存存储、持久化,内存中是断电即失、所以说持久化很重要( rdb、aof )
- 效率高,可以用于高速缓存
- 发布订阅系统.
- 地图信息分析
- 计时器、计数器(浏览量!)
- Redis特性
- 多样的数据类型
- 持久化
- 集群
- 事务
redis中文网:http://www.redis.cn/
推荐都在linux上开发,不推荐在windwos上
Redis安装
使用Redis链接
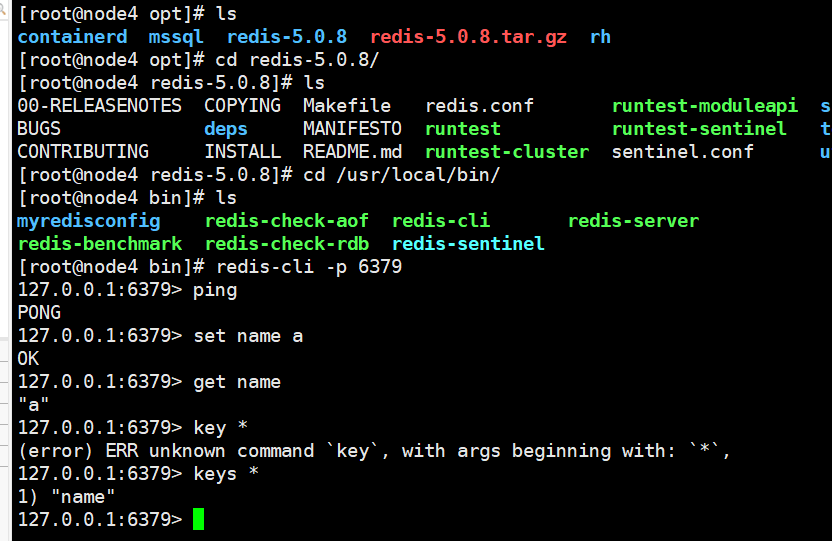
查询是否开启

测试性能
redis-benchmark是官方的性能测试工具
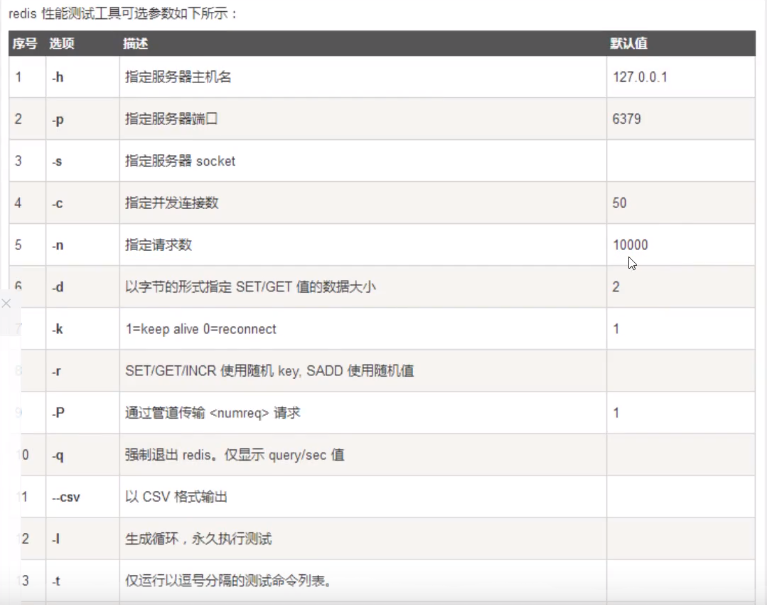
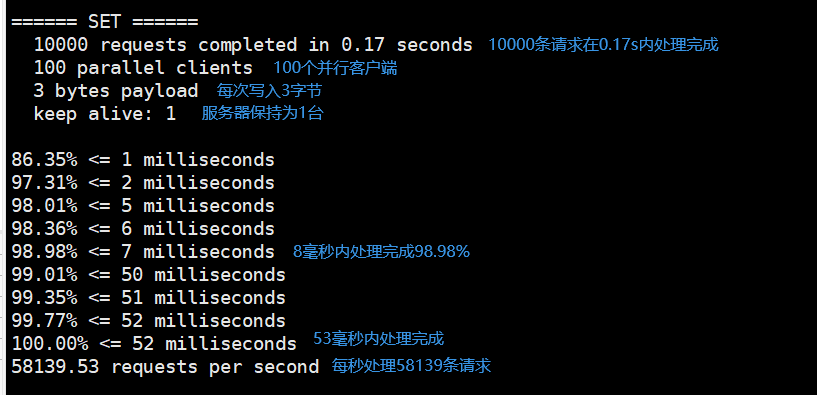
redis-benchmark -h localhost -p 6379 -c 100 -n 10000
基础知识
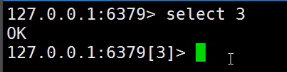
Redis默认有16个数据库,默认使用第0个

使用select 3可以切换到第3个数据库
DBSIZE查看当前数据库大小
keys * 查看数据库所有的key
flushdb清除当前数据库内容
flushall清除全部数据库内容
move name 1 将 name键值对移到数据库1
EXPIRE name 10 name键值对10秒后过期
TYPE name 查看name的类型
EXITS name 判断是否存在键name
Redis是单线程的
- Redis是基于内存操作的,CPU不是CPU的性能瓶颈,瓶颈是机器的内存和网络带宽。
单线程为什么这么快?
误区1.高性能的服务器一定的是多线程的?
误区2.多线程(CPU会上下切换)一定比单线程效率高?
核心:Redis是将所有数据放在内存中的,使用单线程效率高。对于内存系统来说,如果没有.上下文切换效率就是最高的!多次读写都是在一个CPU. 上的,
五大数据类型
String
APPEND key1 hello :往key1值追加hello,如果不存在就创建键值对
strlen key1:获取key1值的长度
incr key1:值加一 值为数字类型
- incrby key1 10:值加10
decr key1:值减一
- decrby key1 10:值加10
GETRANGE key1 0 3:截取0到3字符串
- 127.0.0.1:6379> SUBSTR key1 0 2 "hel"
- substr也可以
SETRANGE key1 1 xx :设置从第2个字符开始后面两个字符为xx
setex key1 30 “hello” : key1 30s后过期
setnx mykey “redis” :如果不存在mykey则添加,再使用setnx mykey “hello”无效。 (分布式锁中常使用)
mset mget 批量设置获取值
1
2
3
4
5
6
7
8
9
10
11
12
13127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k1"
3) "k2"
127.0.0.1:6379> MSETNX k1 v2 k4 v4 //k1存在,后面都不执行
(integer) 0
127.0.0.1:6379> keys *
1) "k3"
2) "k1"
3) "k2"- 设置对象 user:{id}:{field}
1
2
3
4
5
6
7
8
9
10
11
12127.0.0.1:6379> set user:1 {name:zhangsan,age:23}
OK
127.0.0.1:6379> mset user:1:name lisi user:1:name 13
OK
127.0.0.1:6379> get user:1
"{name:zhangsan,age:23}"
127.0.0.1:6379> mset user:1:name lisi user:1:age 13
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "lisi"
2) "13"getset 先获取再设置
1 | |
- String应用场景
- 计数器(微信阅读量)
- 统计多单位数量 uid:123456:follow 0 incr 记录用户被关注数
- 粉丝数
- 对象缓存存储
List
Redis里面,List可以玩成栈,队列,阻塞队列
1 | |
- 小结
- ·他实际上是一个链表,before Node after , left , right 都可以插入值
- ·如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在!
- ·在两边插入或者改动值,效率最高!中间元素,相对来说效率会低一点~
Set
set值不能重复
- sadd 添加元素
- smembers 查看所有元素
- sismember 查看是否有指定元素
- scard 获取元素个数
- srem 移除某个元素
- srandmember sets 2 随机获取2个值
- spop 随机删除元素
- smove set1 set2 2 将set中的2移动到set2
- sdiff set1 set2 :set1对set2的差集
- sinter set1 set2 :set1与set2交集
- sunion set1 set2 :set1与set2并集
1 | |
Hash
map集合。 key-map<string,integer>
- hset user name lisi 添加元素
- HMSET user name1 zhangsan name2 lisi 批量添加元素
- hget user name 获取值
- HGETALL user 获得全部键值对
- hdel user name1 删除name1
- hlen myhash
1 | |
1 | |
hash主要用于存储变更的用户数据,如用户名,年龄等。更适合对象的存储(User)
Zset(有序集合)
在set基础上增加了一个值 如 k1 score v1
1 | |
1 | |
set排序,存储班级成绩表,工资表排序。设置权重(普通消息,重要消息),排行榜。
三种特殊数据类型
geospatial
朋友定位,附近的人,打车距离计算
方法:
1 | |
hyperloglog
做基数统计的算法
优点:
- 占用内存是固定的,2^64不同元素的技术,只需要12KB内存。
统计网页的PV(浏览量),传统方式:SET保存用户id,统计元素数量。但如果保量大量的用户id就比较麻烦。
1 | |
bitmaps
统计疫情感染人数。统计用户信息,活跃人数,不活跃人数,登录人数,未登录人数。打卡
1 | |
事务
Redis单条命令式保存原子性的,但是事务不保证原子性!|
redis事务本质:一组命令的集合。一个事务中的所有命令都会被序列化,在事务执行过程的中,会按照顺序执行!
redis事务特点:
- 一次性
- 顺序性
- 排他性:事务在执行过程中不被其他事务影响。
- 没有隔离级别的概念
所有的命令在事务中,并没有直接被执行!只有发起执行命令的时候才会执行!
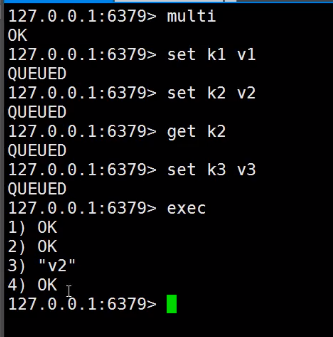
- 开启事务(multi)
- 命令入队(常规命令)
- 执行事务(exec)/放弃事务(discard)
悲观锁乐观锁
- 悲观锁:认为什么时候都会出问题,无论做什么都会加锁。
- 乐观锁:认为什么时候都不会出问题,所以不会上锁。
- 更新数据的时候会判断一下在此期间是否有人修改过这个数据
Redis监视测试
set money 100
watch money;
执行事务。
多线程时,一个线程在执行事务期间另外一个线程修改了数据,由于watch 乐观锁进行了判断,所以事务会执行失败。
Jedis
使用java操作redis中间件
- 导入依赖
1 | |
- 编码测试
- 连接数据库
- 操作命令
- 断开连接
1 | |

1 | |
Springboot整合
SpringBoot2.x之后,Jedis替换成了lettuce
Jedis:采用的直连,多个线程操作的话,是不安全的,如果想要避免不安全的,使用jedis pool连接池!Bio
lettuce:采用netty,实例可以再多个线程中进行共享,不存在线程不安全的情况!可以减少线程数据了,更像Nio模式
- 导入依赖
1 | |
- Redis自动配置类源码
1 | |
- 配置Redis
1 | |
- 测试
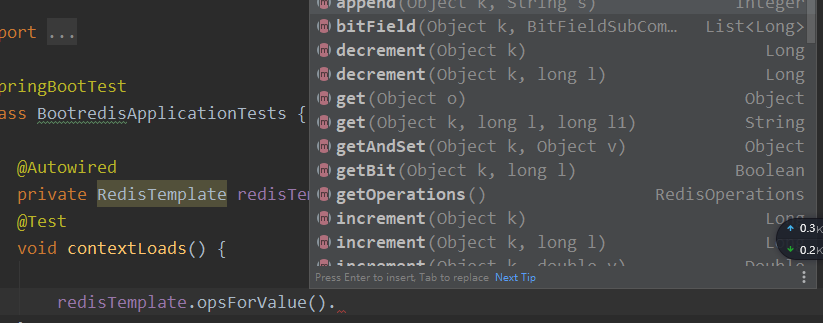
1 | |
Redis.conf详解
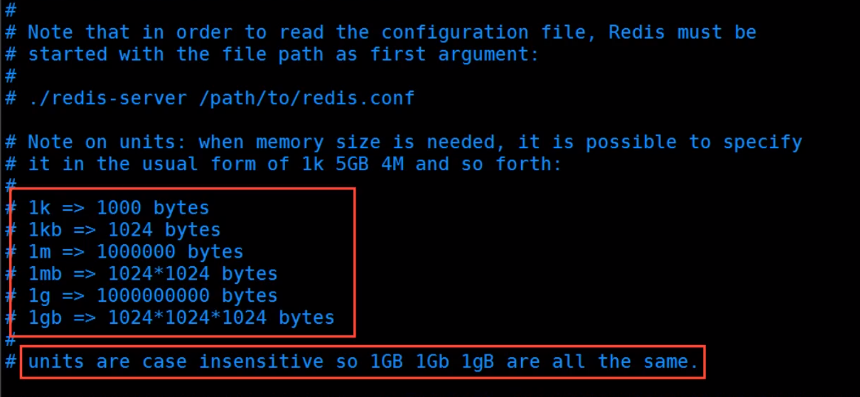
- 单位,不区分大小写
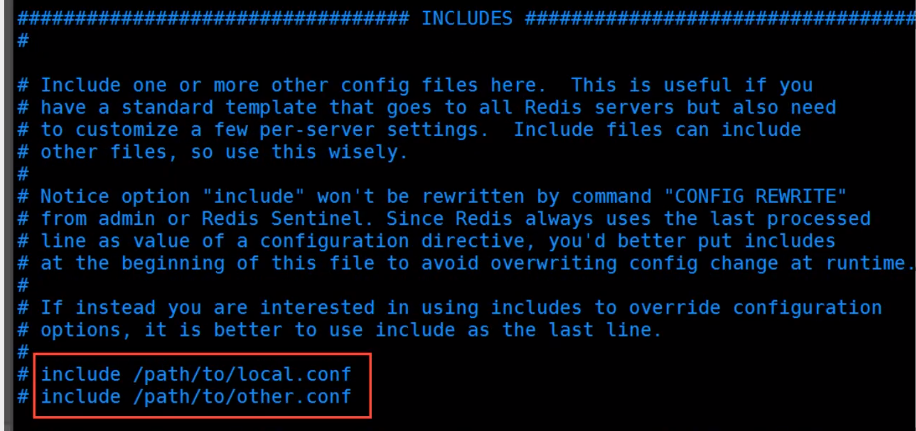
- 包含其他文件
- 网络
bind 127.0.0.1绑定的ip
- 通用
daemonize yes以守护进程的方式运行
pidfile /var/run/redis_6379.pid如果以后台的方式运行需要指定一个pid文件
- 日志

database 16默认16个数据库
- 快照
做持久化,在规定的时间内执行了多少次操作,则会持久化到文件。
save 900 1:如果900s内至少有一个key进行修改,则进行持久化操作
save 300 10:如果300s内至少有10个key进行修改,则进行持久化操作
save 60 10000:如果60s内至少有10000个key进行修改,则进行持久化操作
stop-write-on-bgsave-error yes:持久化如果出错是否需要继续工作
rdbcompression yes:是否压缩rdb文件,需要占用cpu资源
rdbchecksum yes:保存rdb文件的时候,进行错误校验
dir ./:rdb保存的位置
requirepass设置密码。
config set requirepass “123456”
登录:auth 123456
- 限制clients
maxclients 1000设置能连上redis最大客户端数
maxmemory <bytes>:设置redis最大内存容量
maxmemory-policy neoviction:内存达到上限后的处理策略
1 | |
- Append only 模式 aof配置
appendonly no:默认不开启aof模式,默认使用rdb持久化,大部分情况下rdb够用。
appendfilename “appendonly.aof”:持久化文件名字
appendsync everysec:每秒执行一次sync,可能会丢失1s数据
alawys/no
Redis持久化
RDB
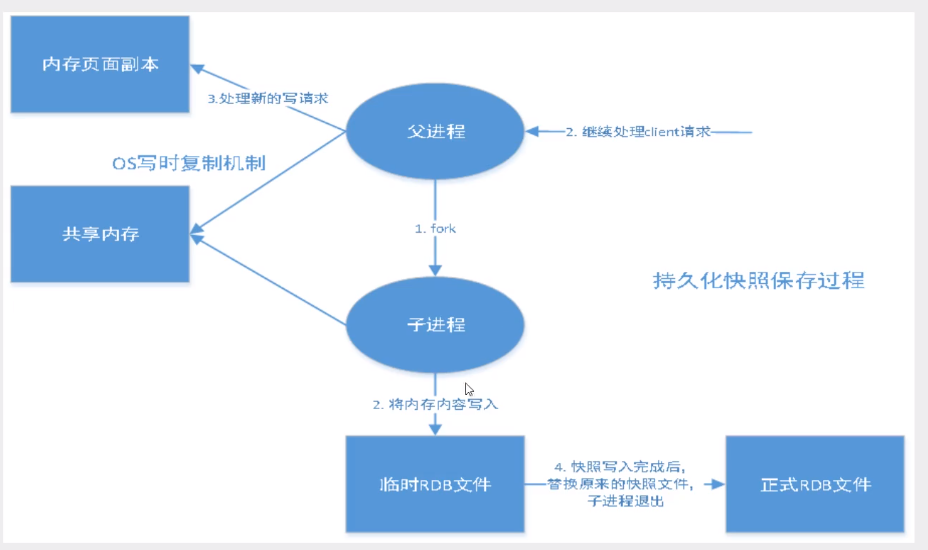
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
Redis会单独创建( fork )一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何I0操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
触发机制
1、save的规则满足的情况下,会自动触发rdb规则 2、执行flushall命令,也会触发我们的rdb规则! 3、退出redis,也会产生rdb文件!
恢复rdb文件
将rdb文件放在redis启动目录就可以

优点:
- 适合大规模的数据恢复
- 对数据的完整性不高。(如果设置60s保存,但在59s时宕机,那么数据就会丢失)
缺点
1、需要一定的时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有的了! 2、fork进程的时候,会占用一定的内容空间!!
AOF(Append Only File)
将我们所有命令记录下来(读操作不记录),然后执行一遍进行追加
默认是不开启的,我们需要手动进行配置!我们只需要将appendonly改为yes就开启了aof
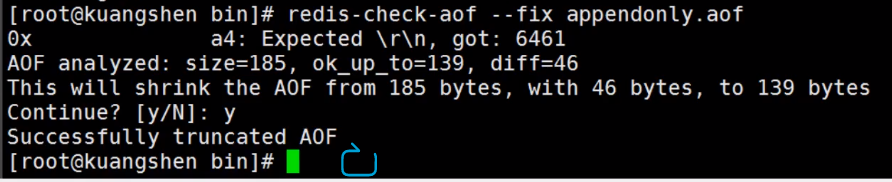
aof文件修复工具redis-check-aof。
删除有错误的命令!
优点
- 每一次修改都同步

- 每秒同步一次,可能会丢失以秒的数据
- 不设置同步,效率最高
缺点
- aof比rdb大得多,运行效率、修复时间也比rdb慢。
重写规则说明

如果文件大于64m,fork一个新的进程来将文件进行重写。
扩展
1、RDB持久化方式能够在指定的时间间隔内对你的数据进行快照存储 2、AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过天。 3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化 4、同时开启两种持久化方式·在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。·RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?作者建议不要,因为RDB更适合 用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。 5、性能建议 ·因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。 如果Enable AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOFrewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。 如果不Enable AOF.仅靠Master-Slave Repllcation实现高可用性也可以,能省掉一大笔lO,也减少了rewrite时带来的系统波动。代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个,微博就是这种架构。
Redis发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式︰发送者(pub)发送消息,订阅者(sub)接收消息。
Redis客户端可以订阅任意数量的频道。
订阅/发布消息图:
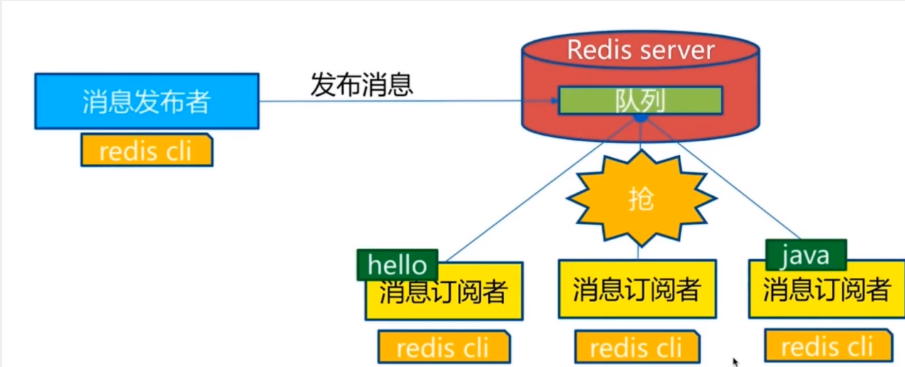
订阅端
1 | |
发送端
1 | |
- 原理
1 | |
- 使用场景
- 实时消息系统
- 实时聊天
- 订阅、关注系统
Redis主从复制
概念
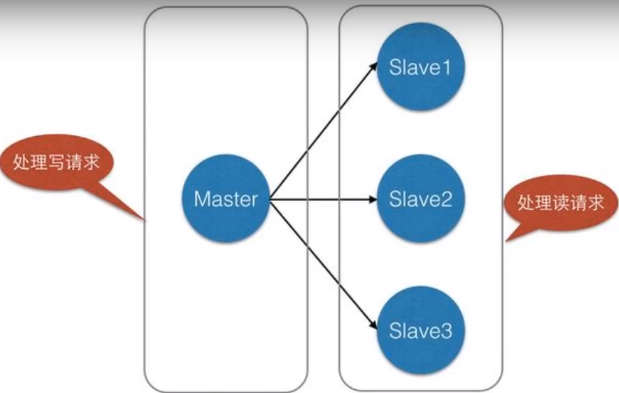
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节(masterleader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。 默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括: 1、数据冗余︰主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。 2、故障恢复∶当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。 3、负载均衡︰在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。 4、高可用基石∶除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下: 1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存, —般来说,单台Redis最大使用内存不应该超过20G。 电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。
环境配置
1 | |
- 复制三个配置文件,修改对应信息
- 端口
- pid名称
- log文件名称
- dump.rdb名称

1 | |
一般在文件中配置
replication

注意
- 主机可以写,从机只能读。
1
2
3127.0.0.1:6380> set k1 v1
(error) READONLY You can't write against a read only replica.- 主机的所有信息都会被从机保存
复制原理
Slave启动成功连接到master后会发送一个部sync命令 Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
slave no one:当主机宕机后,手动将本台机器变为主机,其他从机自动连本台主机。如果原来的主机恢复了,就恢复==原来的主从关系==。
哨兵模式
自动选老大的模式
概述
主从切换技术的方法是∶当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。谋朝篡位的自动版,能够==后台监控主机是否故障==,如果故障了根据==投票数==自动将从库转换为主库。哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个==独立的进程==,作为进程,它会独立运行。其原理是==哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。==
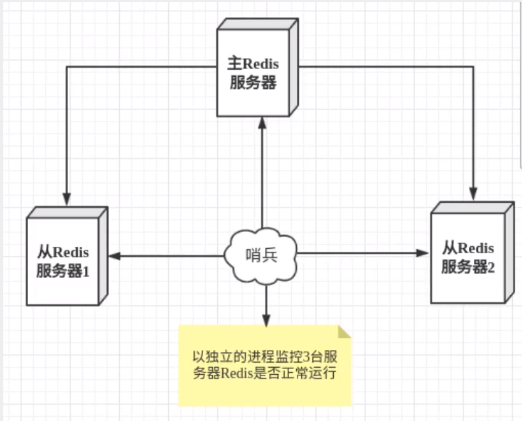
- 哨兵有两个作用
- 通过发送命令,监控redis主服务器和从服务器的运行状态
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过==发布订阅模式==通知其他的从服务器,==修改配置文件==,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了==多哨兵模式==。
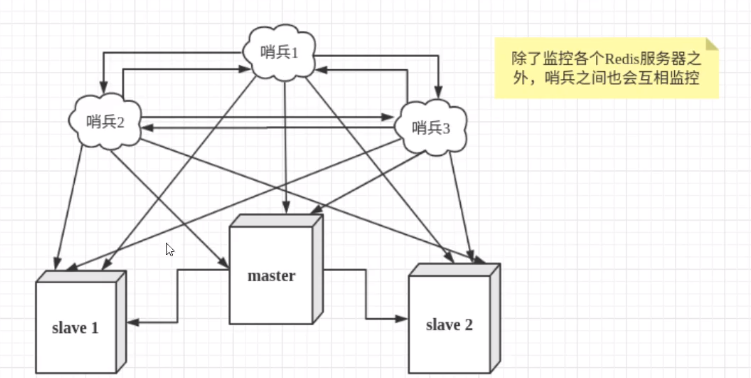
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为==主观下线==。当后面的哨兵也检测到主服务器不可用,并且==数量达到一定值==时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为==客观下线==。
配置
1.配置哨兵配置文件sentinel.conf
1 | |
2.启动哨兵
1 | |
- 效果
1 | |
1 | |
1 | |
- 如果重启主机,则会成为新主机的从机
1 | |
优缺点
- 优点
- 哨兵集群基于主从复制模式,具有主从配置的所有优点
- 主从可以切换,故障可以转移,系统可用性会更好
- 哨兵模式就是主从模式的升级,手动到自动更加健壮
- 缺点
- Redis不好在线扩容,集群一旦达到上限扩容就非常麻烦
- 哨兵模式配置比较麻烦
哨兵模式全部配置
1 | |
Redis缓存穿透和雪崩(面试高频、工作常用)
服务的高可用问题
Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是==数据的一致性==问题,从严格意义上讲,这个问题无解。==如果对数据的一致性要求很高,那么就不能使用缓存。==
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
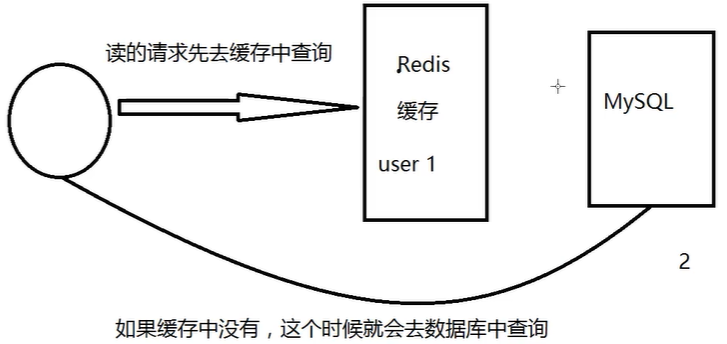
缓存穿透(查不到)
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是==缓存没有命中,于是向持久层数据库查询。发现也没有==,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会==给持久层数据库造成很大的压力==,这时候就相当于出现了缓存穿透。
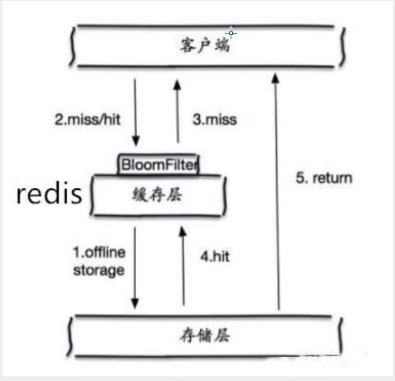
解决方案
1.布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的压力。
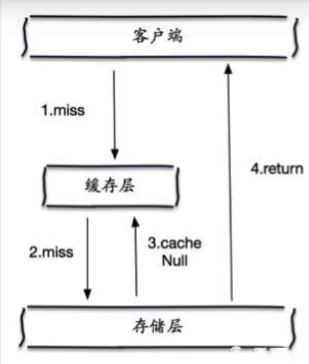
2.缓存空对象
当存储层不命中后,==即使返回的空对象也将其缓存起来==,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是存在两个问题
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中==可能会有很多的空值的键;==
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会==有一段时间窗口的不一致==,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期)
概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,==持续的大并发就穿破缓存,直接请求数据库==,就像在一个屏障上凿开了一个洞。 当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大。
解决方案
1.设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生的问题。
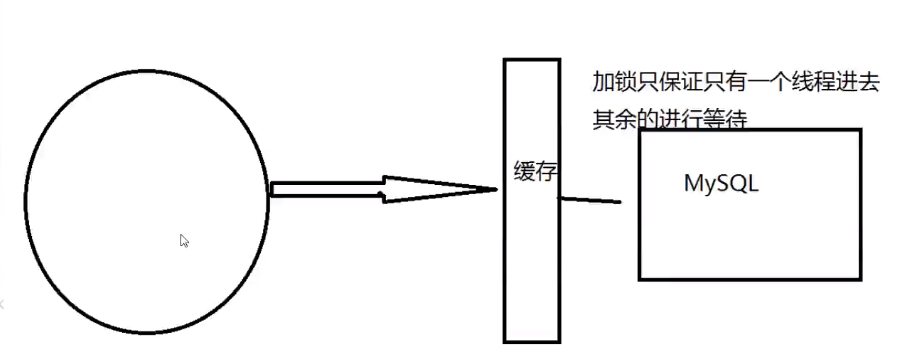
2.加互斥锁
分布式锁∶使用分布式锁,保证对于每个key同时==只有一个线程去查询后端服务==,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
概念
缓存雪崩,是指在某一个时间段,==缓存集中过期失效==。Redis宕机!I
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
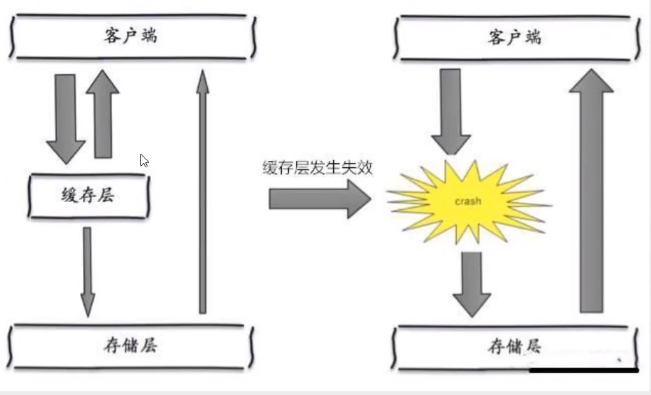
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案
1.redis高可用
搭建redis集群。(异地多活)
2.限流降级
这个解决方案的思想是,在缓存失效后,通过==加锁或者队列来控制读数据库写缓存的线程数量==。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
3.数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前==手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀==
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!