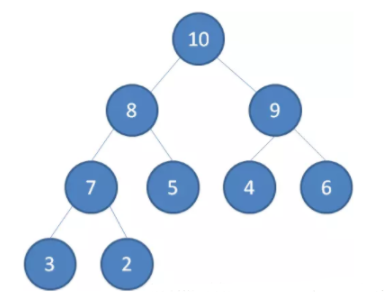
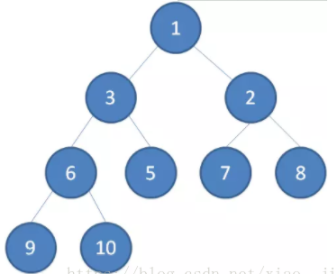
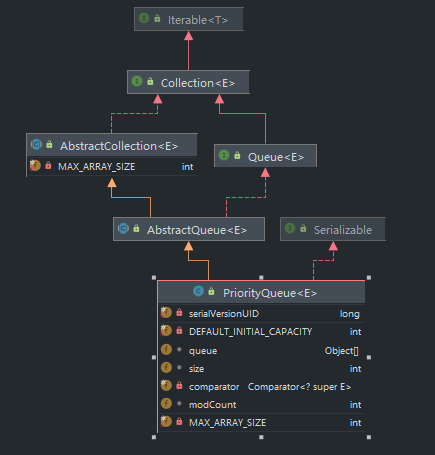
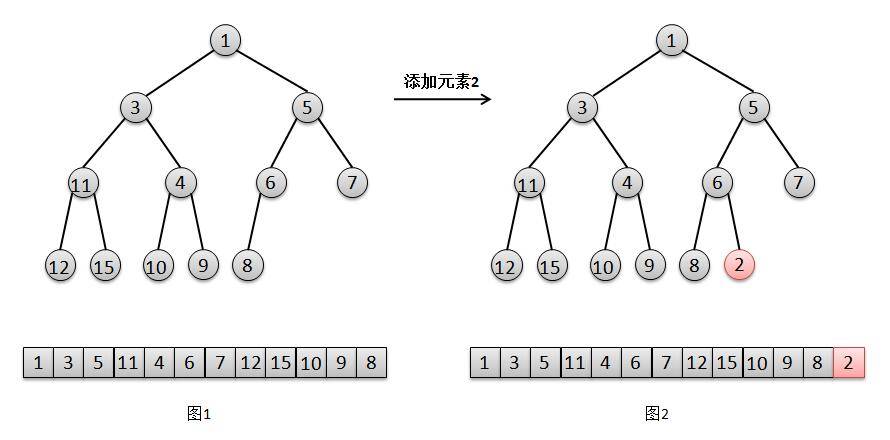
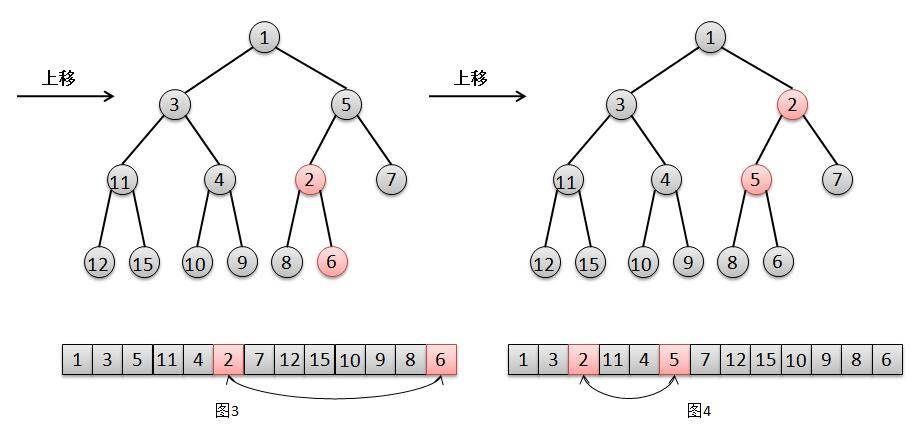
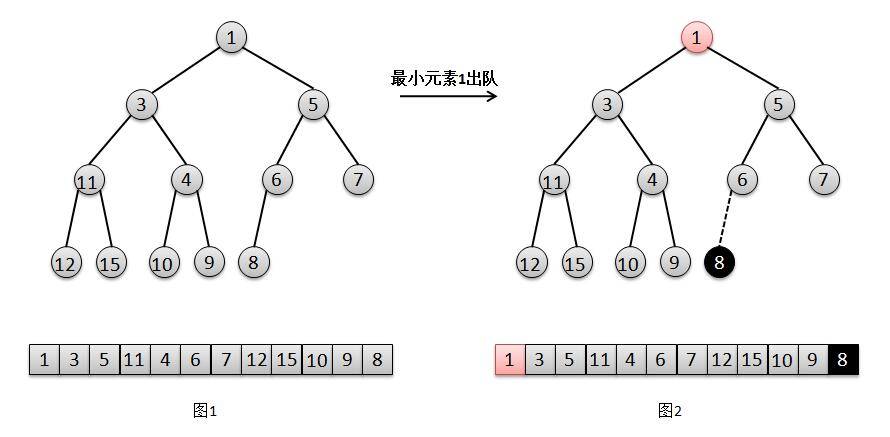
/** * Priority queue represented as a balanced binary heap: the two * children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The * priority queue is ordered by comparator, or by the elements' * natural ordering, if comparator is null: For each node n in the * heap and each descendant d of n, n <= d. The element with the * lowest value is in queue[0], assuming the queue is nonempty. * 英文注释的意思即,是数组实现的二叉堆,对于数组中某个元素queue[n],其左孩子在queue[2n+1]位置上,右孩子queue[2(n+1)]位置,它的父亲则在queue[(n-1)/2]上,而根的位置则是[0]。 */ transient Object[] queue; // non-private to simplify nested class access // 队列中元素大小 int size; // 比较器 privatefinal Comparator<? super E> comparator;
transientint modCount; // non-private to simplify nested class access
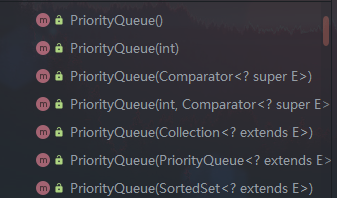
// 指定比较器,初始容量默认11 publicPriorityQueue(Comparator<? super E> comparator) { this(DEFAULT_INITIAL_CAPACITY, comparator); }
// 指定初始容量、也指定比较器 publicPriorityQueue(int initialCapacity, Comparator<? super E> comparator) { // Note: This restriction of at least one is not actually needed, // but continues for 1.5 compatibility if (initialCapacity < 1) thrownewIllegalArgumentException(); this.queue = newObject[initialCapacity]; this.comparator = comparator; }
/** * Creates a {@code PriorityQueue} containing the elements in the * specified collection. If the specified collection is an instance of * a {@link SortedSet} or is another {@code PriorityQueue}, this * priority queue will be ordered according to the same ordering. * Otherwise, this priority queue will be ordered according to the * {@linkplain Comparable natural ordering} of its elements. * 英文注释大致意思就是如果传入的集合c是有序集合或者是另外一个priorityQueue,那么就按照原来的顺序进行排列,否则按照自然排序的方式排列 */ publicPriorityQueue(Collection<? extends E> c) { if (c instanceof SortedSet<?>) { SortedSet<? extendsE> ss = (SortedSet<? extendsE>) c; this.comparator = (Comparator<? super E>) ss.comparator(); initElementsFromCollection(ss); } elseif (c instanceof PriorityQueue<?>) { PriorityQueue<? extendsE> pq = (PriorityQueue<? extendsE>) c; this.comparator = (Comparator<? super E>) pq.comparator(); initFromPriorityQueue(pq); } else { this.comparator = null; initFromCollection(c); } }
// 传入一个PriorityQueue,重新建立堆,深拷贝一个。 publicPriorityQueue(PriorityQueue<? extends E> c) { this.comparator = (Comparator<? super E>) c.comparator(); initFromPriorityQueue(c); }
// 传入一个已经排序的Set,根据其排序规则创建PriorityQueue publicPriorityQueue(SortedSet<? extends E> c) { this.comparator = (Comparator<? super E>) c.comparator(); initElementsFromCollection(c); }
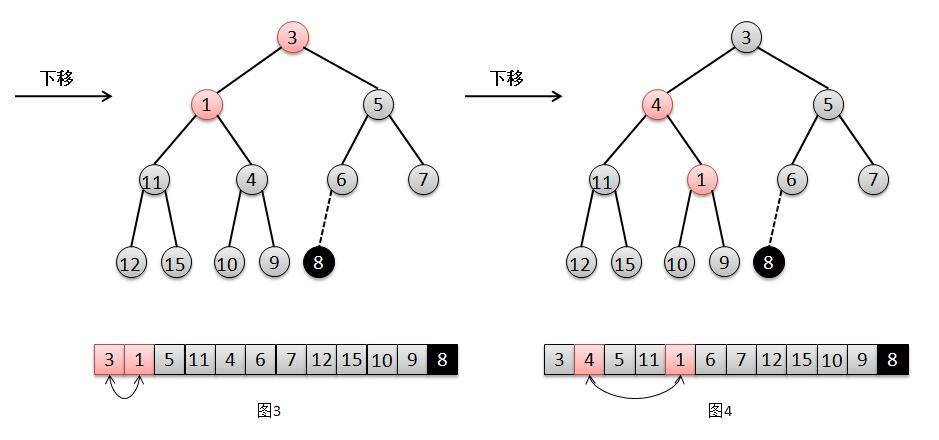
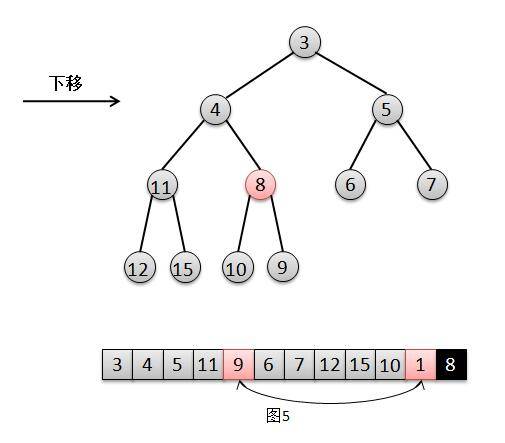
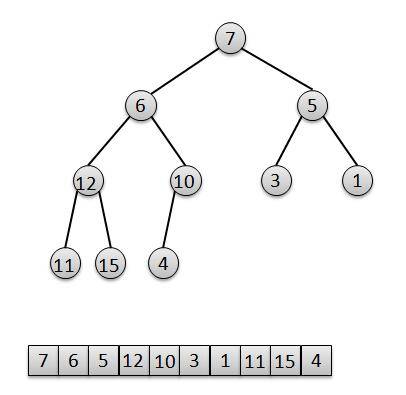
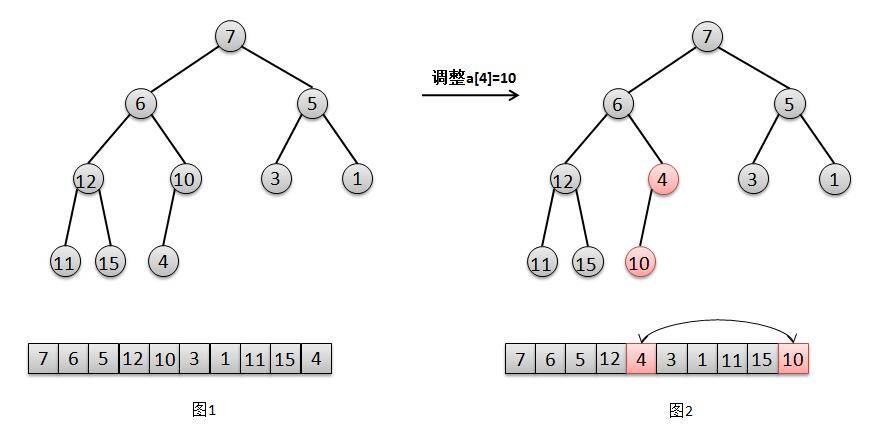
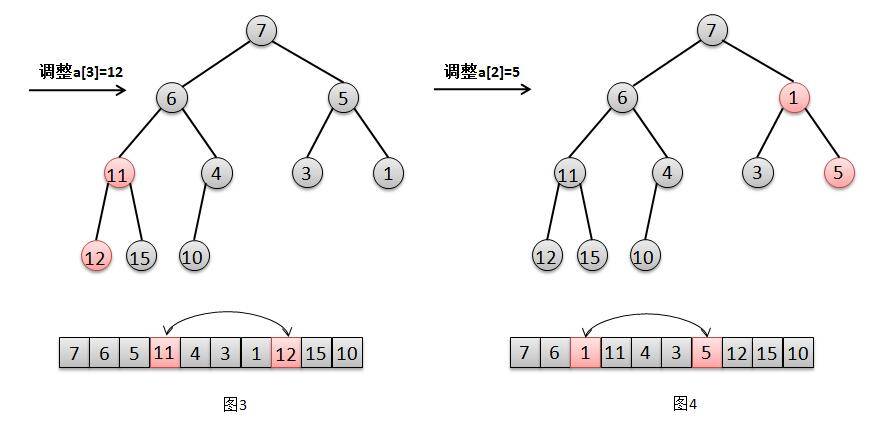
privatevoidheapify() { final Object[] es = queue; // i是为了找寻最后一个非叶子节点,然后倒序进行"下移"siftDown操作 intn= size, i = (n >>> 1) - 1; final Comparator<? super E> cmp; if ((cmp = comparator) == null) for (; i >= 0; i--) siftDownComparable(i, (E) es[i], es, n); else for (; i >= 0; i--) siftDownUsingComparator(i, (E) es[i], es, n, cmp); }