ConcurrentHashMap源码分析(待续)
概要
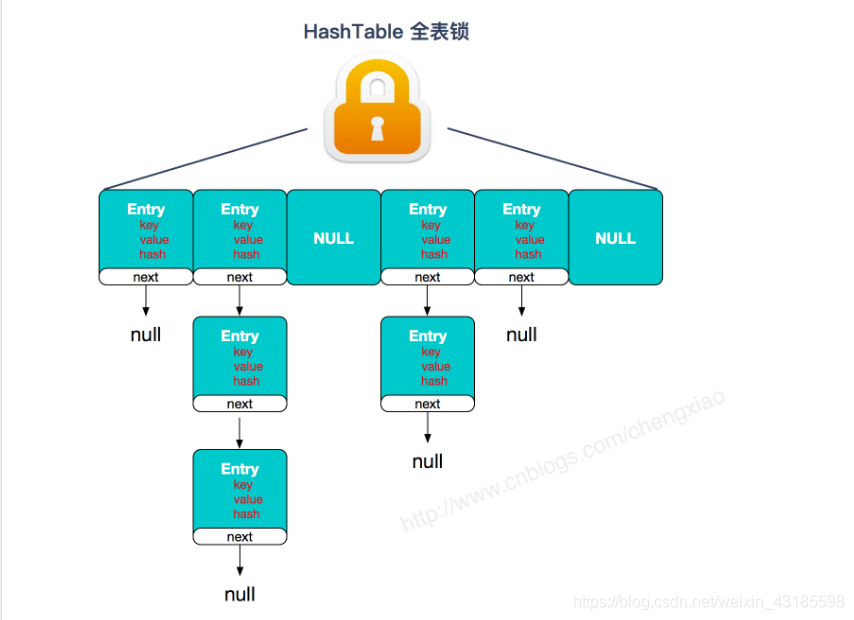
HashTable虽然是线程安全的,但是并发操作时是全表锁,性能非常低下
HashTable线程安全
HashMap操作高效,但是并发操作不能保证线程安全,JDK1.7之前采用头插法扩容时可能会形成环状链表,导致get操作时CUP空转。所以为了解决HashMap线程安全问题,ConcurrentHashMap就诞生了。
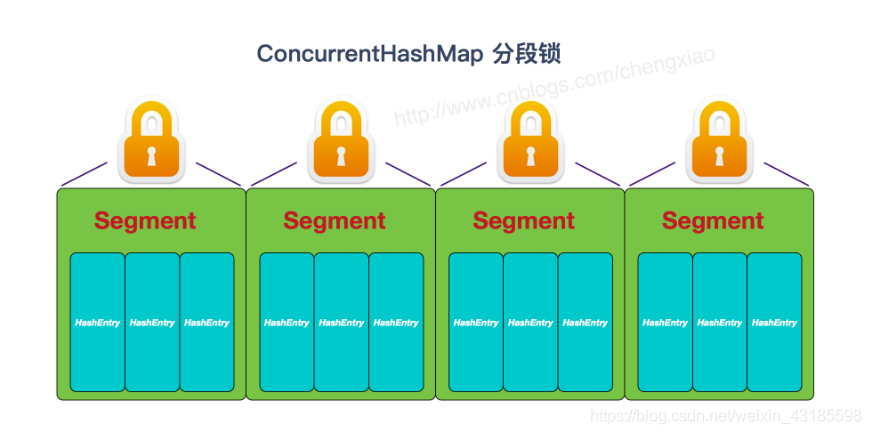
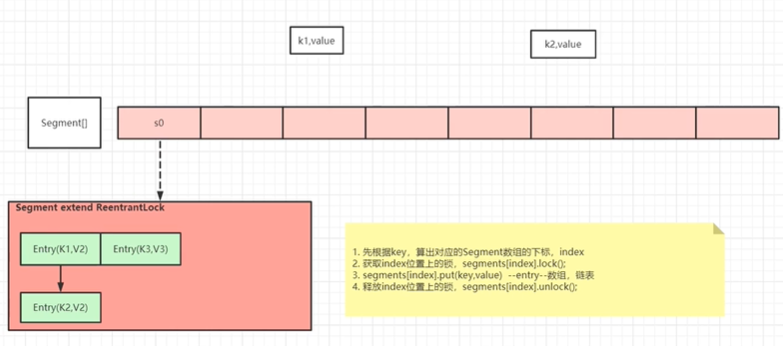
ConcurrentHashMap在JDK1.8之前使用分段锁 来保证线程安全,如下
JDK1.8前使用分段锁
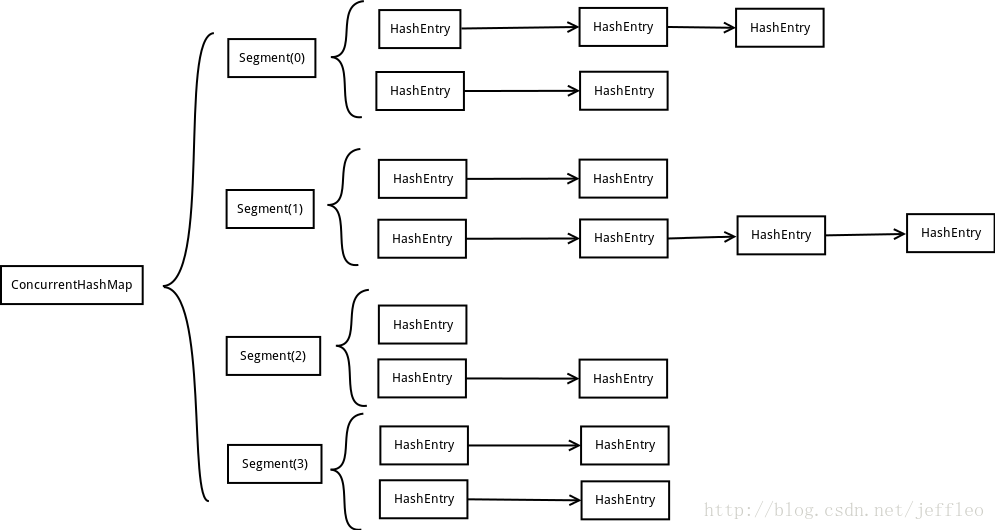
分段
但是JDK1.8版本实现线程安全的思想完全改变,抛弃了分段锁的概念,使用了全新的利用CAS算法 实现。
结构认识
image-20210614104117695
image-20210614104240146
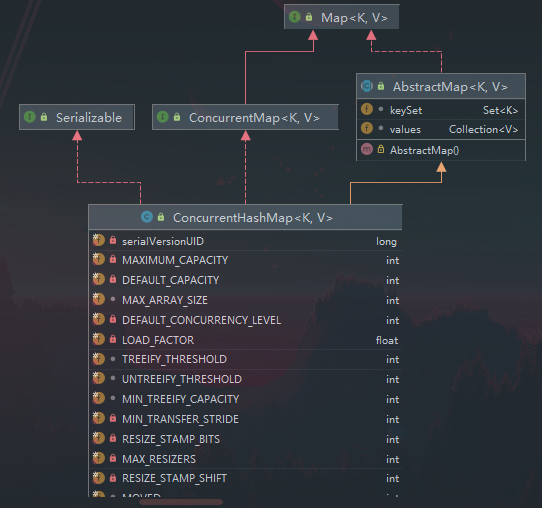
ConcurrentHashMap实现了ConcurrentHashMap接口,但是没有实习Cloneable接口
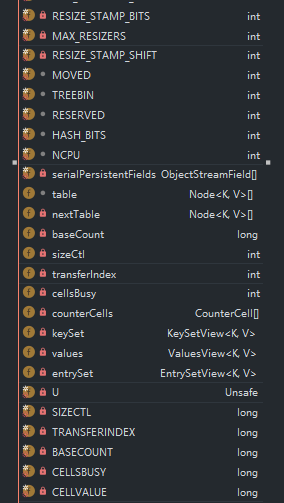
可以看到ConcurrentHashMap有很多的字段,很多都非常陌生,我们一个个来解释。
源码解释
字段解释
常规常量:(HashMap中的常量不作赘述,需要了解可移步JDK1.8HashMap源码通俗解读 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private static final int MAXIMUM_CAPACITY = 1 << 30 ;private static final int DEFAULT_CAPACITY = 16 ;static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;private static final int DEFAULT_CONCURRENCY_LEVEL = 16 ;private static final float LOAD_FACTOR = 0.75f ;static final int TREEIFY_THRESHOLD = 8 ;static final int UNTREEIFY_THRESHOLD = 6 ;static final int MIN_TREEIFY_CAPACITY = 64 ;private static final int MIN_TRANSFER_STRIDE = 16 ;private static final int RESIZE_STAMP_BITS = 16 ;private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1 ;private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
下面几个是特殊的节点的hash值,正常节点的hash值在hash函数中都处理过了,不会出现负数的情况,特殊节点在各自的实现类中有特殊的遍历方法
static final int MOVED = -1 ; static final int TREEBIN = -2 ; static final int RESERVED = -3 ; static final int HASH_BITS = 0x7fffffff ;
普通链表节点:通常是桶中元素小于8个 ,就是一个单链表,头元素hash > 0。
转移节点(MOVED):
表明当前正在扩容中,当前的节点元素已经被转移到新table中,头元素hash =-1。
树节点(TREEBIN):
表示当前的桶是一个红黑树桶 ,头元素hash = -2。
占位节点(RESERVED):一般用于当key对应的值缺失 需要计算的场景,在计算出新值之前临时占坑位用的,计算出来之后就用普通Node节点替换掉,头元素hash = -3。
static final int NCPU = Runtime.getRuntime().availableProcessors();
字段: 重点认识sizeCtl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 transient volatile Node<K,V>[] table;private transient volatile Node<K,V>[] nextTable;private transient volatile long baseCount;private transient volatile int sizeCtl;private transient volatile int transferIndex;private transient volatile int cellsBusy;private transient volatile CounterCell[] counterCells;
存储结构解释
1、Node:基本节点/普通节点
此节点就是一个很普通的Entry,在链表形式保存才使用这种节点,它存储实际的数据,基本结构类似于1.8的HashMap.Node,和1.7的Concurrent.HashEntry。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 static class Node <K,V> implements Map .Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;int hash, K key, V val) {this .hash = hash;this .key = key;this .val = val;int hash, K key, V val, Node<K,V> next) {this (hash, key, val);this .next = next;public final K getKey () { return key; }public final V getValue () { return val; }public final int hashCode () { return key.hashCode() ^ val.hashCode(); }public final String toString () {return Helpers.mapEntryToString(key, val);public final V setValue (V value) {throw new UnsupportedOperationException ();public final boolean equals (Object o) {return ((o instanceof Map.Entry) &&null &&null &&find (int h, Object k) {this ;if (k != null ) {do {if (e.hash == h &&null && k.equals(ek))))return e;while ((e = e.next) != null );return null ;
2、TreeNode:红黑树节点
在红黑树形式保存时才存在,它也存储有实际的数据,结构和1.8的HashMap的TreeNode一样,一些方法的实现代码也基本一样。不过,ConcurrentHashMap对此节点的操作,都会由TreeBin来代理执行。也可以把这里的TreeNode看出是有一半功能的HashMap.TreeNode,另一半功能在ConcurrentHashMap.TreeBin中。
红黑树节点本身保存有普通链表节点Node的所有属性,因此可以使用两种方式进行读操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static final class TreeNode <K,V> extends Node <K,V> {boolean red;int hash, K key, V val, Node<K,V> next,super (hash, key, val, next);this .parent = parent;find (int h, Object k) {return findTreeNode(h, k, null );final TreeNode<K,V> findTreeNode (int h, Object k, Class<?> kc) {if (k != null ) {this ;do {int ph, dir; K pk; TreeNode<K,V> q;if ((ph = p.hash) > h)else if (ph < h)else if ((pk = p.key) == k || (pk != null && k.equals(pk)))return p;else if (pl == null )else if (pr == null )else if ((kc != null ||null ) &&0 )0 ) ? pl : pr;else if ((q = pr.findTreeNode(h, k, kc)) != null )return q;else while (p != null );return null ;
3、ForwardingNode:转发节点
ForwardingNode是一种临时节点,在扩容进行中 才会出现,hash值固定为-1 ,并且它不存储 实际的数据数据。如果旧数组的一个hash桶中全部的节点都迁移到新数组中,旧数组就在这个hash桶中放置一个ForwardingNode。读操作或者迭代读时碰到ForwardingNode时,将操作转发到扩容后的新的table数组 上去执行,写操作碰见它时,则尝试帮助扩容 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static final class ForwardingNode <K,V> extends Node <K,V> {final Node<K,V>[] nextTable;super (MOVED, null , null );this .nextTable = tab;find (int h, Object k) {for (Node<K,V>[] tab = nextTable;;) {int n;if (k == null || tab == null || (n = tab.length) == 0 ||1 ) & h)) == null )return null ;for (;;) {int eh; K ek;if ((eh = e.hash) == h &&null && k.equals(ek))))return e;if (eh < 0 ) {if (e instanceof ForwardingNode) {continue outer;else return e.find(h, k);if ((e = e.next) == null )return null ;
4、TreeBin:代理操作TreeNode的节点
TreeBin的hash值固定为-2 ,它是ConcurrentHashMap中用于代理 操作TreeNode的特殊节点,持有存储实际数据的红黑树的根节点 。因为红黑树进行写入操作,整个树的结构可能会有很大的变化,这个对读线程有很大的影响,所以TreeBin还要维护一个简单读写锁 ,这是相对HashMap,这个类新引入这种特殊节点的重要原因。
static final class TreeBin <K,V> extends Node <K,V> {volatile TreeNode<K,V> first; volatile Thread waiter; volatile int lockState; static final int WRITER = 1 ; static final int WAITER = 2 ; static final int READER = 4 ;
5、ReservationNode:保留节点
或者叫空节点,computeIfAbsent和compute这两个函数式api中才会使用。它的hash值固定为-3 ,就是个占位符,不会保存实际的数据 ,正常情况是不会出现的,在jdk1.8新的函数式有关的两个方法computeIfAbsent和compute中才会出现。
为什么需要这个节点,因为正常的写操作,都会想对hash桶的第一个节点进行加锁,但是null是不能加锁 ,所以就要new一个占位符出来,放在这个空hash桶中成为第一个节点,把占位符当锁的对象,这样就能对整个hash桶加锁了。put/remove不使用ReservationNode是因为它们都特殊处理 了,并且这种特殊情况实际上还更简单,put直接使用cas操作,remove直接不操作,都不用加锁。但是computeIfAbsent和compute这个两个方法在碰见这种特殊情况时稍微复杂些,代码多一些,不加锁不好处理,所以需要ReservationNode来帮助完成对hash桶的加锁操作。
static final class ReservationNode <K,V> extends Node <K,V> {super (RESERVED, null , null );find (int h, Object k) {return null ;
构造函数解释
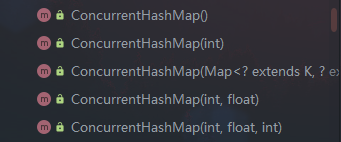
ConcurrentHashMap中一共有5个构造函数
image-20210614112920296
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public ConcurrentHashMap () {public ConcurrentHashMap (int initialCapacity) {this (initialCapacity, LOAD_FACTOR, 1 );public ConcurrentHashMap (Map<? extends K, ? extends V> m) {this .sizeCtl = DEFAULT_CAPACITY;public ConcurrentHashMap (int initialCapacity, float loadFactor) {this (initialCapacity, loadFactor, 1 );public ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0.0f ) || initialCapacity < 0 || concurrencyLevel <= 0 )throw new IllegalArgumentException ();if (initialCapacity < concurrencyLevel) long size = (long )(1.0 + (long )initialCapacity / loadFactor);int cap = (size >= (long )MAXIMUM_CAPACITY) ?int )size);this .sizeCtl = cap;
JDK1.7中concurrencyLevel表示有多少个Segment,有多少个Segment就表示支持多少个线程可以并发操作,initialCapacity表示每个Segment中有多少个Entry对象。
并发级别不会随扩容变化。
image-20210614114657389
可以看到JDK1.8中虽然保留了Segment,但是构造函数直接将concurrencyLevel赋值给了initialCapacity,没有使用JDK1.7的思想。
构造函数不会进行初始化,只是进行参数的设定,真正初始化在initTable()。在put方法中有调用此方法,即第一次put才进行初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private final Node<K,V>[] initTable() {int sc;while ((tab = table) == null || tab.length == 0 ) {if ((sc = sizeCtl) < 0 )else if (U.compareAndSetInt(this , SIZECTL, sc, -1 )) {try {if ((tab = table) == null || tab.length == 0 ) {int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked") new Node <?,?>[n];2 );finally {break ;return tab;
初始化调用时机
基本方法解释
hash扰动函数,跟1.8的HashMap的基本一样,& HASH_BITS用于把hash值转化为正数 ,负数hash是有特别作用
static final int HASH_BITS = 0x7fffffff ; static final int spread (int h) {return (h ^ (h >>> 16 )) & HASH_BITS;
comparableClassFor()用于获取Comparable接口中的泛型类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static Class<?> comparableClassFor(Object x) {if (x instanceof Comparable) {if ((c = x.getClass()) == String.class) return c;if ((ts = c.getGenericInterfaces()) != null ) {for (Type t : ts) {if ((t instanceof ParameterizedType) &&null &&1 && as[0 ] == c) return c;return null ;
compareComparables()同1.8的HashMap,当类型相同且实现Comparable时,调用compareTo比较大小
@SuppressWarnings({"rawtypes","unchecked"}) static int compareComparables (Class<?> kc, Object k, Object x) {return (x == null || x.getClass() != kc ? 0 : ((Comparable)k).compareTo(x));
下面几个用于读写table数组,使用Unsafe提供的更强的功能(数组元素的volatile读写,CAS
更新)代替普通的读写,调用者预先进行参数控制
static final <K,V> Node<K,V> tabAt (Node<K,V>[] tab, int i) {return (Node<K,V>)U.getReferenceAcquire(tab, ((long )i << ASHIFT) + ABASE);static final <K,V> boolean casTabAt (Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {return U.compareAndSetReference(tab, ((long )i << ASHIFT) + ABASE, c, v);static final <K,V> void setTabAt (Node<K,V>[] tab, int i, Node<K,V> v) {long )i << ASHIFT) + ABASE, v);
计数操作
由于ConcurrentHashMap是一个高并发的集合,集合中增删就比较频繁,那计数就变成了一个问题,如果使用像AtomicInteger这样类型的变量来计数,虽然可以保证原子性,但是太多线程去竞争CAS,自旋也挺浪费时间的,所以ConcurrentHashMap使用了一种类似LongAddr的数据结构去计数,其实LongAddr是继承Striped64,有关于这个类的原理大家可以参考这篇文章:并发之STRIPED64(累加器)和
LONGADDER ,大家了解了这个类的原理,理解ConcurrentHashMap计数就没有一点压力了,因为两者在代码实现上基本一样。
实现计数原理的字段如下:
private transient volatile long baseCount;private transient volatile CounterCell[] counterCells;@jdk .internal.vm.annotation.Contended static final class CounterCell {volatile long value;long x) { value = x; }
baseCount:基础计数,线程如果进行put等操作,使用CAS修改baseCount即可
counterCells:分段计数的数组,根据hash值让线程在数组上不同索引处计数,类似JDK1.7的Segment分段锁,给线程分配一个Segment,这里给线程分配一个索引进行独自计数。
根据STRIPED64和LONGADDR的思想,高并发环境下计数先会尝试使用CAS无锁技术对baseCount进行更新,但是如果自旋过久就判定竞争很激烈,此时才会使用counterCells进行计数。最后使用一定的方法将counterCells的计数值和baseCount总和起来。
总和的方法就是sumCount()
final long sumCount () {long sum = baseCount;if (cs != null ) {for (CounterCell c : cs)if (c != null )return sum;
高并发下的计数流程大致了解了,我们深入一下。
刚刚谈到竞争激烈情况下才会使用counterCells进行计数,那么线程怎么直到我要把计数放在哪里呢?这和探针hash 有关。这个值比较有趣,分析代码的时候我们再说。
我们看看计数+1的具体代码addCount()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 private final void addCount (long x, int check) {long b, s;if ((cs = counterCells) != null ||this , BASECOUNT, b = baseCount, s = b + x)) {long v; int m;boolean uncontended = true ;if (cs == null || (m = cs.length - 1 ) < 0 ||null ||return ;if (check <= 1 )return ;if (check >= 0 ) {int n, sc;while (s >= (long )(sc = sizeCtl) && (tab = table) != null &&int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;if (sc < 0 ) {if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||null || transferIndex <= 0 )break ;if (U.compareAndSetInt(this , SIZECTL, sc, sc + 1 ))else if (U.compareAndSetInt(this , SIZECTL, sc, rs + 2 ))null );
注意到一句代码c = cs[ThreadLocalRandom.getProbe() & m]) == null,根据方法名可以猜到是获取一个随机值生成探针,为什么要使用ThreadLocalRandom,而不直接使用Random,因为每个线程都是隔离的,只需要知道自己应该在哪个位置计数就可以了,所以使用ThreadLocal线程内部变量即可。还有一个关键就是随机数Random的生成需要一个种子,默认是当前时机毫秒值。如果初始化Random,种子(seed1)为当前时间戳,另外一个线程需要计算随机数,需要使用CAS更新当前种子生成seed2,然后再生成随机数。
问题就出在CAS,高并发情况下都维护一个seed会非常影响性能,所以使用ThreadLocalRandom可以保证每个线程维护自己内部私有的种子即可,不存在竞争修改种子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 private final void fullAddCount (long x, boolean wasUncontended) {int h;if ((h = ThreadLocalRandom.getProbe()) == 0 ) {true ;boolean collide = false ; for (;;) {int n; long v;if ((as = counterCells) != null && (n = as.length) > 0 ) {if ((a = as[(n - 1 ) & h]) == null ) {if (cellsBusy == 0 ) { CounterCell r = new CounterCell (x); if (cellsBusy == 0 &&this , CELLSBUSY, 0 , 1 )) {boolean created = false ;try { int m, j;if ((rs = counterCells) != null &&0 &&1 ) & h] == null ) {true ;finally {0 ;if (created)break ;continue ; false ;else if (!wasUncontended) true ; else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))break ;else if (counterCells != as || n >= NCPU)false ; else if (!collide)true ;else if (cellsBusy == 0 &&this , CELLSBUSY, 0 , 1 )) {try {if (counterCells == as) {new CounterCell [n << 1 ];for (int i = 0 ; i < n; ++i)finally {0 ;false ;continue ; else if (cellsBusy == 0 && counterCells == as &&this , CELLSBUSY, 0 , 1 )) {boolean init = false ;try { if (counterCells == as) {new CounterCell [2 ];1 ] = new CounterCell (x);true ;finally {0 ;if (init)break ;else if (U.compareAndSwapLong(this , BASECOUNT, v = baseCount, v + x))break ;
方法流程梳理如下:
判断数组是否为空,为空的话初始化数组
如果数组存在,通过探针hash定位桶中的位置,如果桶中为空,新建节点,通过CAS锁插入数组,如果成功,结束,如果失败转到第5步
如果定位到桶中有值,通过CAS修改,如果成功,结束,如果失败向下走
如果数组大小小于CPU核数,扩容数组
重新计算探针hash
扩容
JDK1.8的扩容可以多线程一起完成,因此变得复杂了,但是效率提升了。
transfer任务
由字面意思可以知道transfer是转移的意思,这里指代扩容时多线程中每个线程分配的迁移原结点到新结点处 的任务
对于一个大任务拆分成多个小任务供多线程执行,一般都要求这些小任务具有相似性,流程一致 ,并且很重要的一点,任务之间的相互影响尽量少。那么在扩容之中,是怎么划分这个任务的呢?
对于一般扩容,大致分为两步:
新建一个2倍大小的数组,这个过程要求单线程完成,多线程没有意义,反而容易出错。
迁移原数组结点到新数组,即rehash过程,我们知道HashMap中使用了一个技巧避免重新计算hash值,即使用(e.hash & oldCap) == 0判断新索引处于高位还是低位。
这一点对多线程扩容非常有利。根据这一点,可以知道,每个hash桶的迁移都可以作为一个线程在扩容时的一个transfer任务。
另外,每个线程要任务都不应该规模太小,因为扩容并不是IO型 操作,节点迁移的执行速度本身很快,太多的线程来执行节点迁移,线程调度开销 占比变大,反而降低了吞吐量。ConcurrentHashMap这里,会根据CPU的核心数目(前面提到的NCPU),来算出一个transfer任务包含的hash桶的数量。
transfer()中会计算每个transfer任务中要迁移多少个hash桶,一个transfer任务完成后,可以再次申请,这个方法代码非常多,先省略后面的部分。
private final void transfer (Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;if ((stride = (NCPU > 1 ) ? (n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE)
MIN_TRANSFER_STRIDE我们知道代表一次transfer中最小迁移的hash桶数量,默认为16.即一次迁移任务中最少应该迁移16个hash桶。
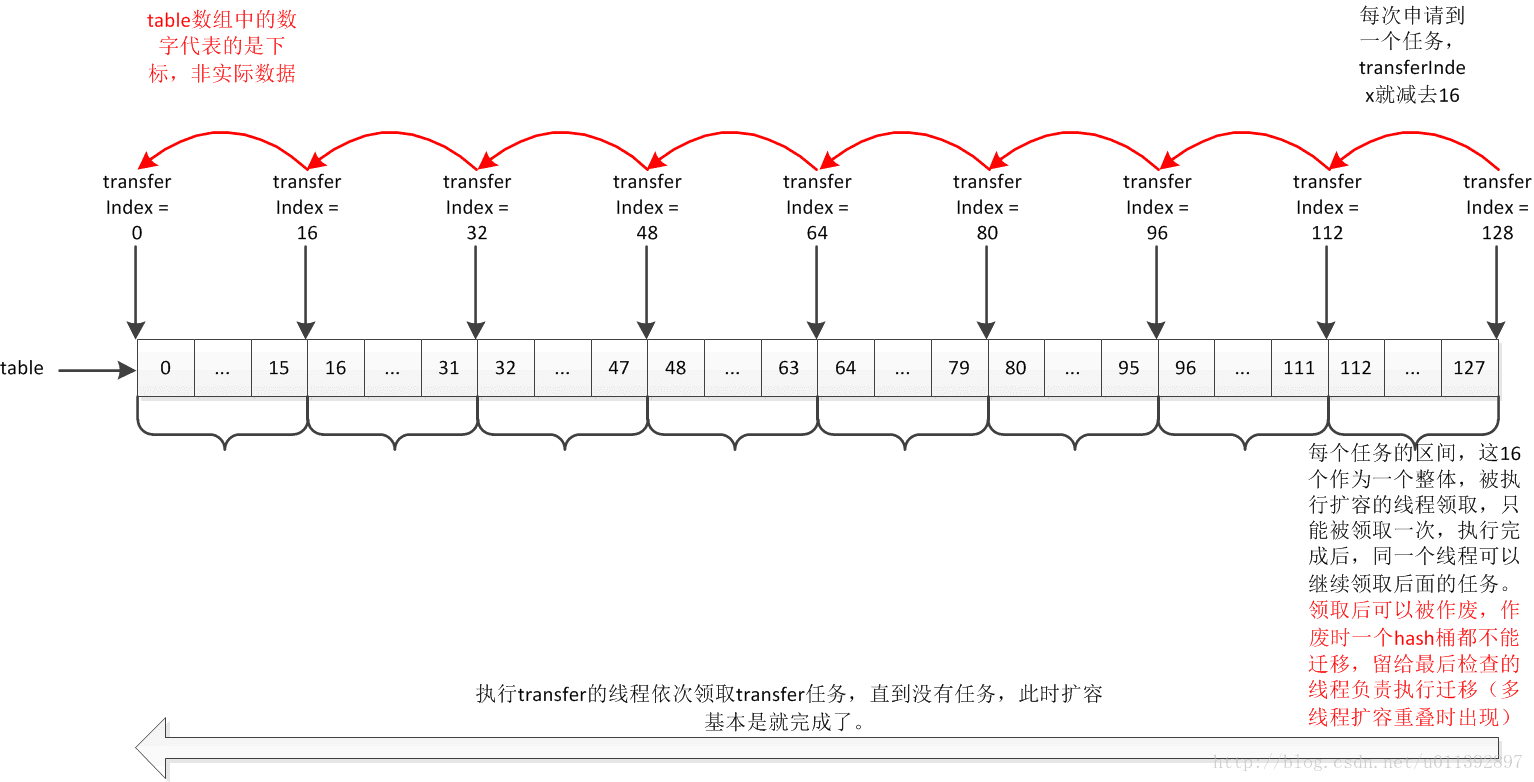
申请transfer任务
private transient volatile int transferIndex;
还记得这个变量吗?它的意思就是用于标记整体的transfer进行到了哪里,申请transfer任务跟它关联非常大。
经典生产者消费者中,消费者会从任务队列里去获取可执行任务,因此MQ、Redis应对高并发的思想也是通过队列来进行控制。ConcurrentHashMap中不存在队列,因为底层的数组就可以实现队列,通过transferIndex来控制任务的调度。
每次申请任务,transferIndex就会-1。由于迭代操作是从小到大,为了减少和扩容时transfer的迭代发生冲突,transferIndex采取反向迭代,即下标从大到小。二者相遇后,要transfer的hash桶都已经被遍历过了,要遍历的的hash桶都已经tranfer完成到新数组了,这样减少了冲突。
下标在[transferIndex - stride(>= 0), transferIndex - 1]内的hash桶,就是每个transfer的任务区间 。transferIndex
<= 0
时,代表没有任务 可以申请,此时无法帮助扩容。注意,NCPU不一定是2^n,因此最后一个任务中的hash桶的数量可能不足stride 个,此时只执行余下的数量。
为了保证每个任务只被领取一次,transferIndex递减是用CAS操作完成的。
特殊情况下,会出现多线程扩容重叠,此时某个transfer任务虽然被领取了,但是却不能被执行,会被作废。这是根据transfer方法的代码理解得到的,因为transfer方法的代码中有考虑任务作废的情况。
简而言之就是:代码中有处理扩容作废,但是实际不会发生。
transfer任务申请流程图(源自网络)