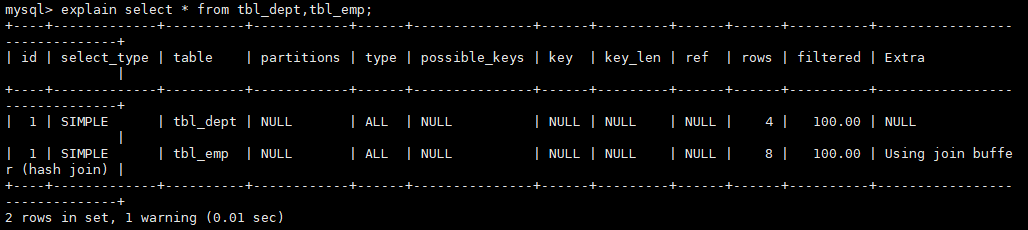
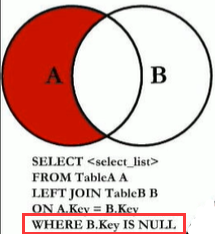
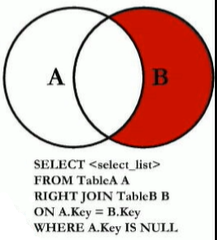
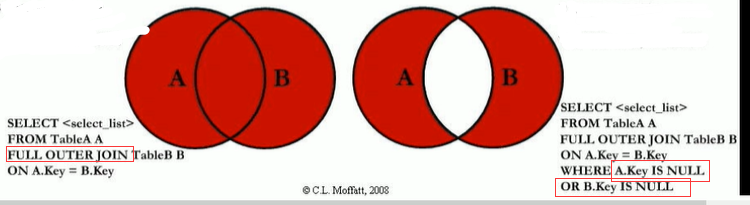
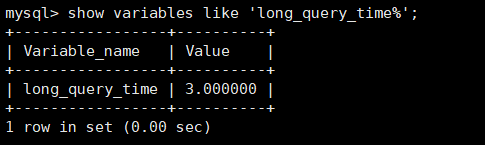
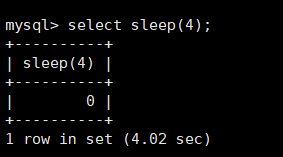
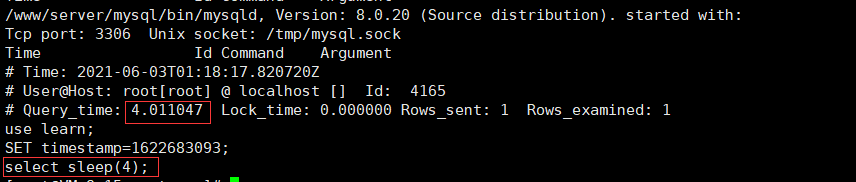
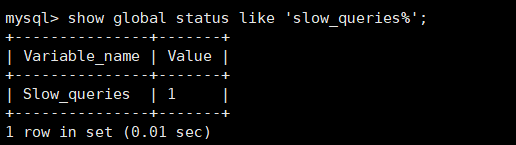
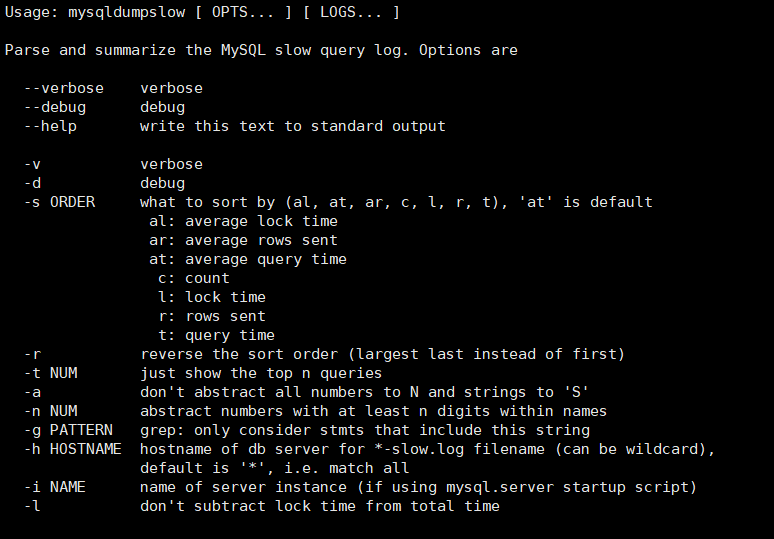
MySQL不支持全外连接,使用union联合left join
和 right join,union自带去重
索引优化
单表优化案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CREATE TABLE IF NOT EXISTS `article`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `author_id` INT (10) UNSIGNED NOT NULL, `category_id` INT(10) UNSIGNED NOT NULL , `views` INT(10) UNSIGNED NOT NULL , `comments` INT(10) UNSIGNED NOT NULL, `title` VARBINARY(255) NOT NULL, `content` TEXT NOT NULL );
CREATE TABLE IF NOT EXISTS `class`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL );
CREATE TABLE IF NOT EXISTS `book`( `bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL );
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
查询语句:explain select * from class left join book on class.card = book.card;
分析结果:
image-20210531140622529
查询type是全表查询,需要优化
优化过程
对于此左连接查询,首先我们尝试给右表book连接的字段加索引create index idx_book_card on book(card)
CREATE TABLE IF NOT EXISTS `phone`( `phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL )ENGINE = INNODB;
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
查询语句:select * from class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;
查询分析:
image-20210531155054223
发现全部都是全表扫描,性能非常不好。
优化过程
首先根据上一个案例,我们对右表,即book和phone的连接字段各自建立索引。
1 2
create index idx_book_card on book(card); create index idx_phone_card on phone(card);
image-20210531155341186
发现总查询次数减少了很多次,优化效果很好。
总结
对于Join语句的优化
尽可能减少Join语句中NestedLoop循环总次数;永远用小结果集驱动大结果集
优先优化NestedLoop中的内层循环
保证Join语句中被驱动表上的Join条件字段已经被索引
当无法保证被驱动表的Join字段被索引且内存资源充足的前提下,可以多使用JoinBuffer的设置
索引失效
1 2 3 4 5 6 7 8 9 10 11 12
CREATE TABLE staffs( id INT PRIMARY KEY AUTO_INCREMENT, `name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名', `age` INT NOT NULL DEFAULT 0 COMMENT'年龄', `pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位', `add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间' )CHARSET utf8 COMMENT'员工记录表'; INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW()); INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW()); INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`)
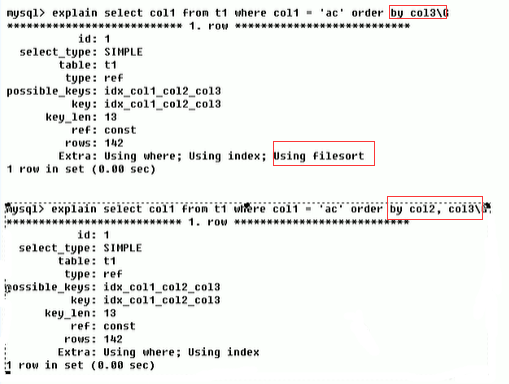
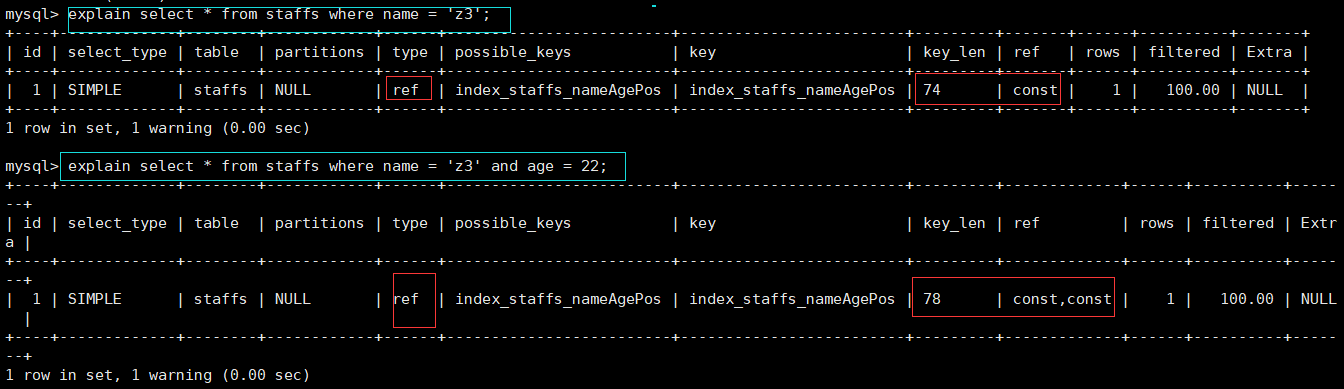
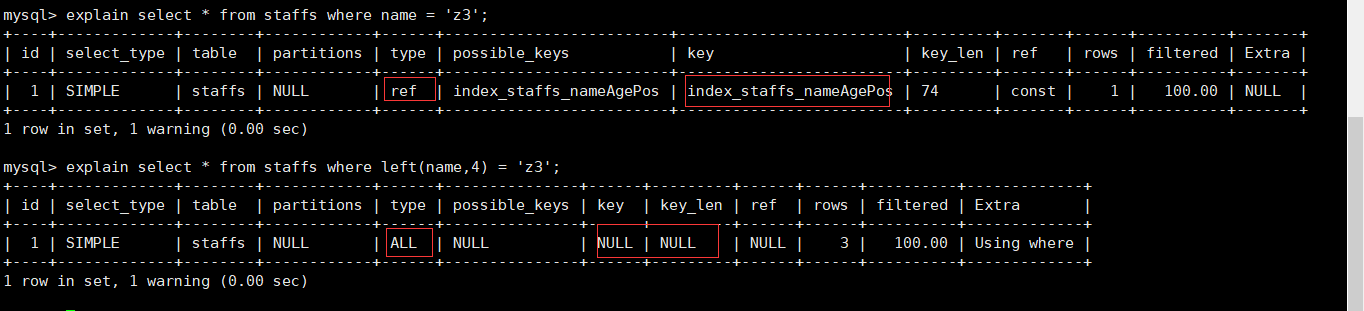
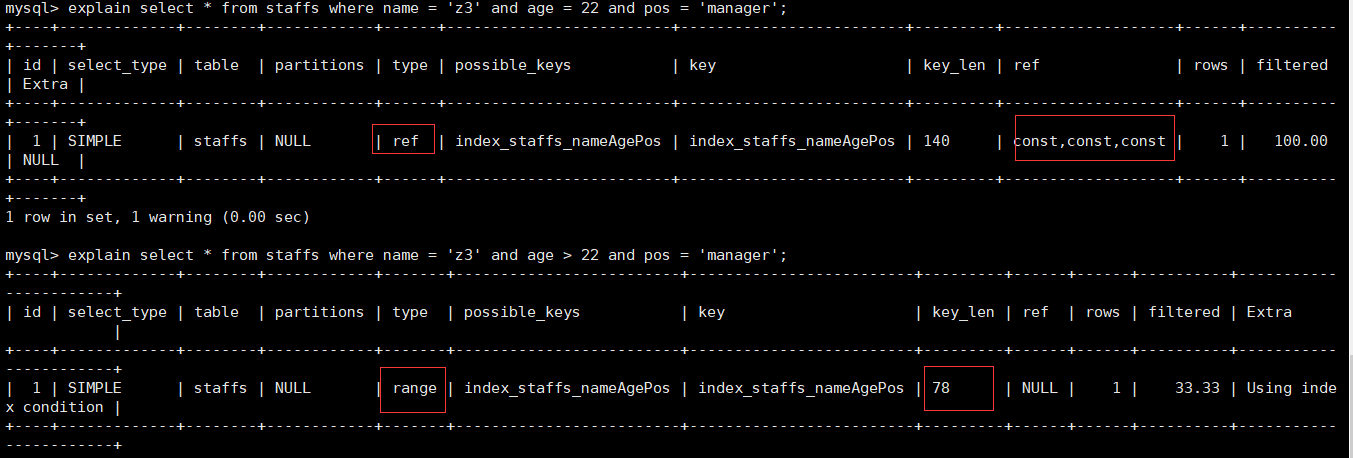
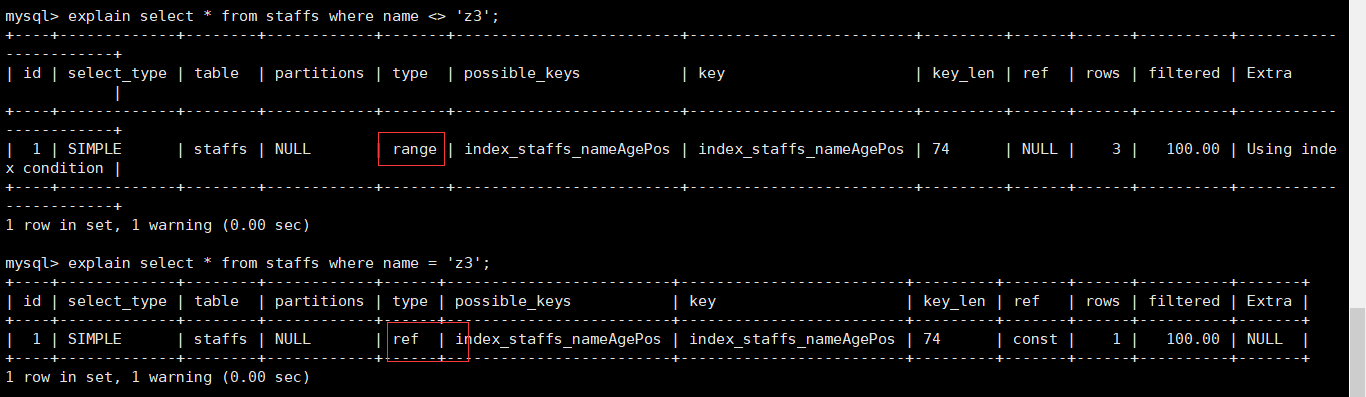
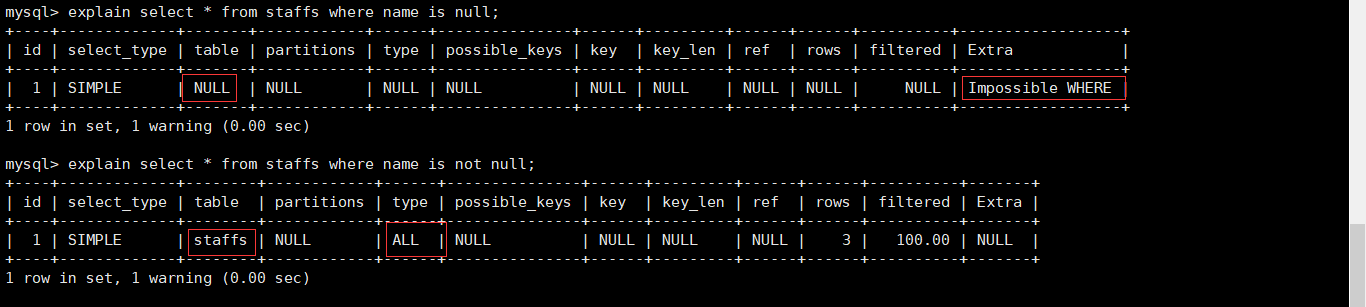
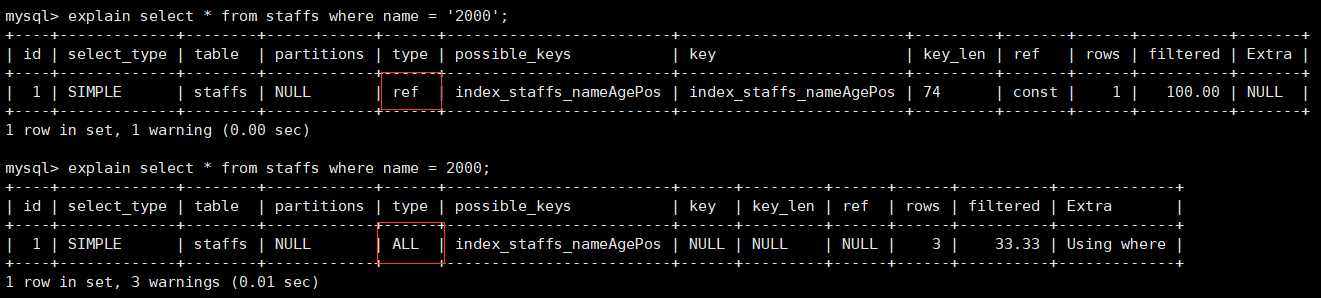
非全值匹配,违背最左前缀法则
对于上面的表,我们建立了ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(name,age,pos)三列的复合索引。
create table dept( id int unsigned primary key auto_increment, deptno mediumint unsigned not null default 0, dname varchar(20) not null default "", loc varchar(13) not null default "" )engine=innodb default charset=GBK;
CREATE TABLE emp( id int unsigned primary key auto_increment, empno mediumint unsigned not null default 0, ename varchar(20) not null default "", job varchar(9) not null default "", mgr mediumint unsigned not null default 0, hiredate date not null, sal decimal(7,2) not null, comm decimal(7,2) not null, deptno mediumint unsigned not null default 0 )ENGINE=INNODB DEFAULT CHARSET=GBK; //函数 delimiter $$ create function ran_string(n int) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i=i+1; end while; return return_str; end $$ //函数 delimiter $$ create function rand_num() returns int(5) begin declare i int default 0; set i=floor(100+rand()*10); return i; end $$ //存储过程 delimiter $$ create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i+1; insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values((start+i),ran_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num()); until i=max_num end repeat; commit; end $$ //存储过程 delimiter $$ create procedure insert_dept(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i+1; insert into dept(deptno,dname,loc) values((start+i),ran_string(10),ran_string(8)); until i=max_num end repeat; commit; end $$
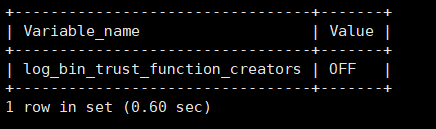
但是在这之前我们需要设置一个参数show variables like 'log_bin_trust_function_creators';;
image-20210603101158350
开启创建函数的权限。
set global log_bin_trust_function_creators = 1;
然后测试调用
image-20210603101408010
image-20210603101423649
可以看到插入50万条数据花费了一分多钟
插入500万数据
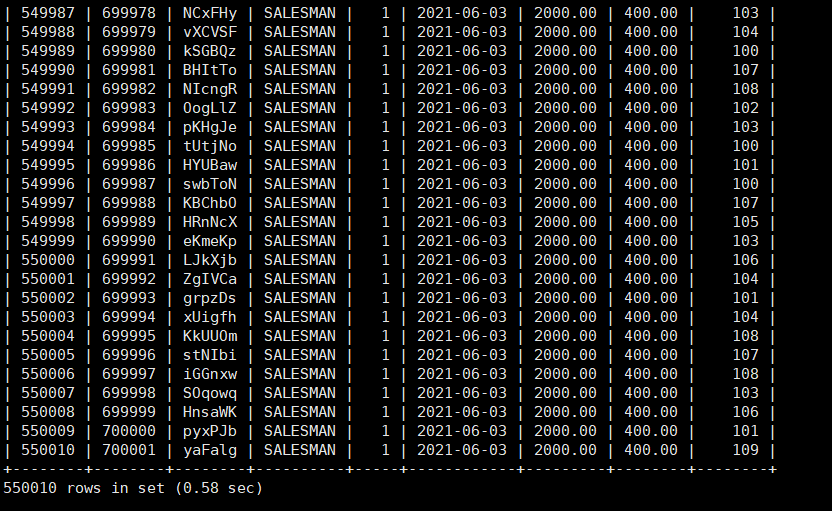
然后我们查询全部。花费了0.58秒?
Show Profile
是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优测量。
默认关闭状态,并保存最近15次的结果。
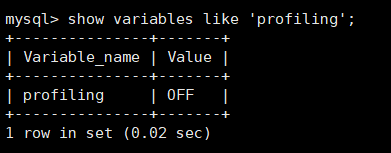
可以用show variables like '%profiling'查看
查询状态
set profiling = on;开启
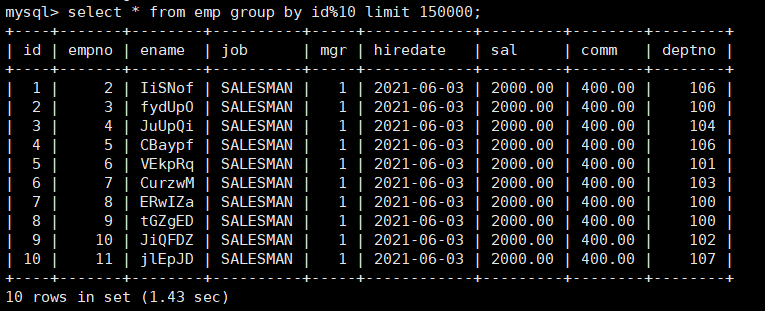
模拟慢查询
select * from emp group by id%10 limit 150000;
花费1.43s
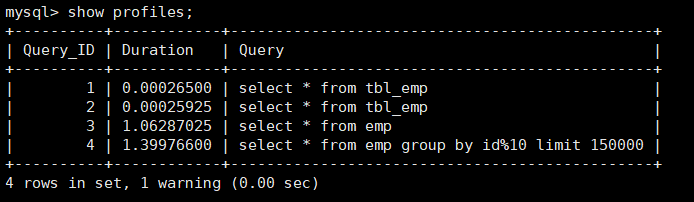
然后我们通过show profiles查看
show profiles
可以看到我们能执行的每一条sql和对应的执行时间
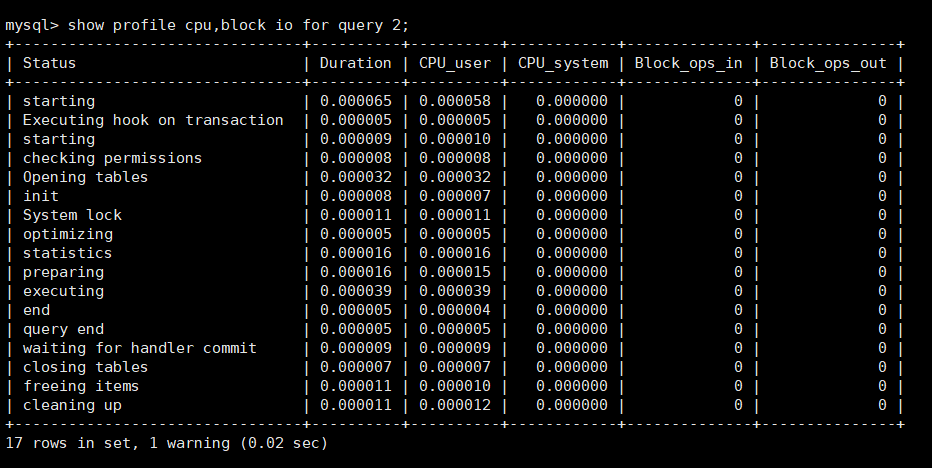
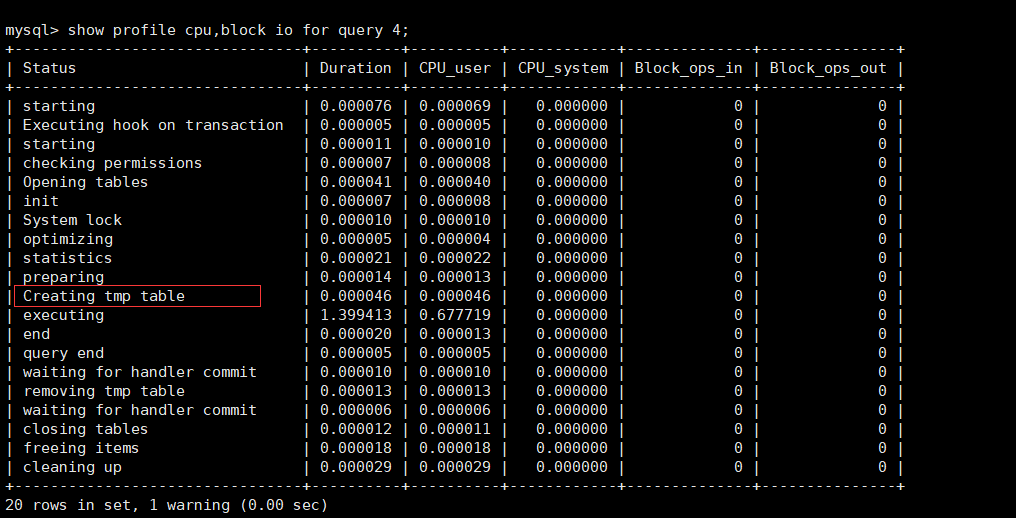
根据每条的执行时间,我们可以通过诊断命令show profile cpu,block io for query [num]查看
converting HEAP to MYISAM :'查询结果太大、开始往磁盘上转移' creating tmp table :'创建临时表,将结果拷贝进临时表,然后再删除临时表' Coping to tmp table on disk :'把内存中的临时表复制进磁盘(危险)' locked :'已经上锁'
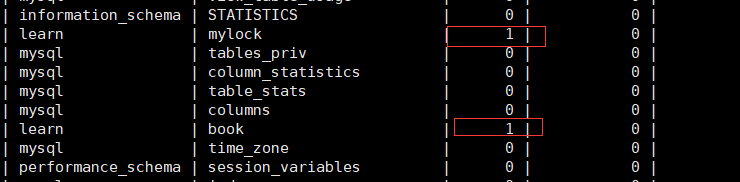
set global general_log = 1; set global out_put = 'TABLE'; #查看日志 select * from mysql.general_log;
数据库锁理论
锁的分类
按对数据的操作类型分
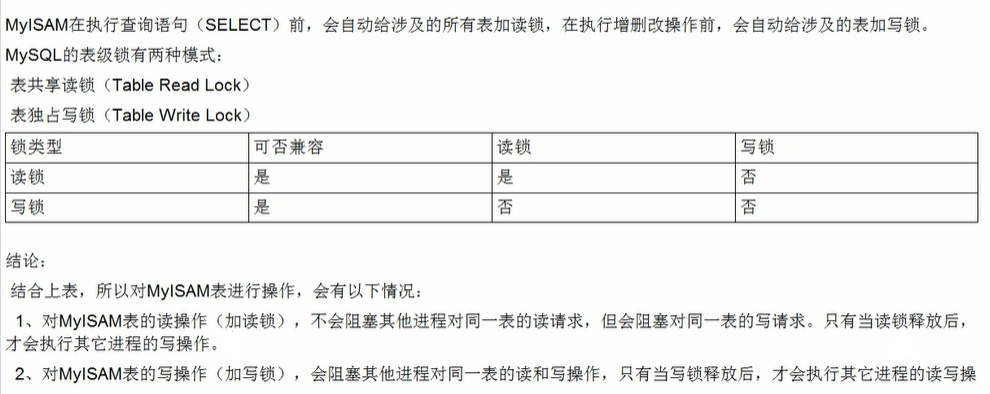
读锁(共享锁):多个读操作可以同时进行而不被影响
写锁(排他锁):当前写操作没有完成前,会阻断其他写操作和读操作。
按对数据操作的粒度分
表锁(偏读)
行锁(偏写)
页锁
读锁
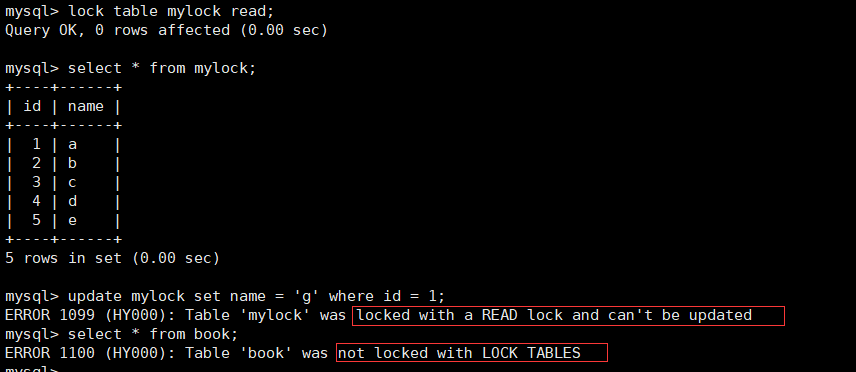
表锁:偏向MyISAM引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低
表锁读锁案例
1 2 3 4 5 6 7 8 9 10
create table mylock ( id int not null primary key auto_increment, name varchar(20) default '' ) engine myisam;
insert into mylock(name) values('a'); insert into mylock(name) values('b'); insert into mylock(name) values('c'); insert into mylock(name) values('d'); insert into mylock(name) values('e');