publicbooleanremove(Object o) { if (o == null) { // 如果被删除的结点值为null(非结点为null) for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { // 遍历找到后调用unlink()删除该结点 unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
清空链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
publicvoidclear() { // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator for (Node<E> x = first; x != null; ) { Node<E> next = x.next; // 逐个将结点的值置为null,引用解除 x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; }
set
1 2 3 4 5 6 7 8
public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); EoldVal= x.item; x.item = element; // 返回旧值 return oldVal; }
添加
1 2 3 4 5 6 7 8 9
publicvoidadd(int index, E element) { checkPositionIndex(index); // 尾部插入 if (index == size) linkLast(element); else // 在index结点前插入,element称为index处的结点 linkBefore(element, node(index)); }
publicintlastIndexOf(Object o) { intindex= size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }
public E peek() { final Node<E> f = first; return (f == null) ? null : f.item; } public E element() { return getFirst(); } public E poll() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); // 去掉头结点 } public E remove() { return removeFirst(); }
//首先获取从辅助方法返回的LinkedList对象,接着把该对象的所有域都设置为初始值。 //然后把LinkedList中所有的内容复制到返回的对象中。 public Object clone() { LinkedList<E> clone = superClone();
// Put clone into "virgin" state clone.first = clone.last = null; clone.size = 0; clone.modCount = 0;
// Initialize clone with our elements for (Node<E> x = first; x != null; x = x.next) clone.add(x.item);
return clone; }
然后是转为数组
1 2 3 4 5 6 7 8
public Object[] toArray() { // Object[],因此可能效率会有些慢 Object[] result = newObject[size]; inti=0; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; return result; }
public <T> T[] toArray(T[] a) { if (a.length < size) // 如果数组大小小于链表长度。利用反射创建一个大小相同的数组 a = (T[])java.lang.reflect.Array.newInstance( a.getClass().getComponentType(), size); inti=0; Object[] result = a; for (Node<E> x = first; x != null; x = x.next) // 然后把链表结点的值依次赋值给数组 result[i++] = x.item; // 如果数组大小大于链表长度,将多余的部分置为null if (a.length > size) a[size] = null;
privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject();
// Write out size s.writeInt(size);
// Write out all elements in the proper order. for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item); }
/** * Reconstitutes this {@code LinkedList} instance from a stream * (that is, deserializes it). */ @SuppressWarnings("unchecked") privatevoidreadObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject();
// Read in size intsize= s.readInt();
// Read in all elements in the proper order. for (inti=0; i < size; i++) linkLast((E)s.readObject()); } privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject();
// Write out size s.writeInt(size);
// Write out all elements in the proper order. for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item); }
/** * Reconstitutes this {@code LinkedList} instance from a stream * (that is, deserializes it). */ @SuppressWarnings("unchecked") privatevoidreadObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject();
// Read in size intsize= s.readInt();
// Read in all elements in the proper order. for (inti=0; i < size; i++) linkLast((E)s.readObject()); } privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject();
// Write out size s.writeInt(size);
// Write out all elements in the proper order. for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item); }
/** * Reconstitutes this {@code LinkedList} instance from a stream * (that is, deserializes it). */ @SuppressWarnings("unchecked") privatevoidreadObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject();
// Read in size intsize= s.readInt();
// Read in all elements in the proper order. for (inti=0; i < size; i++) linkLast((E)s.readObject()); }
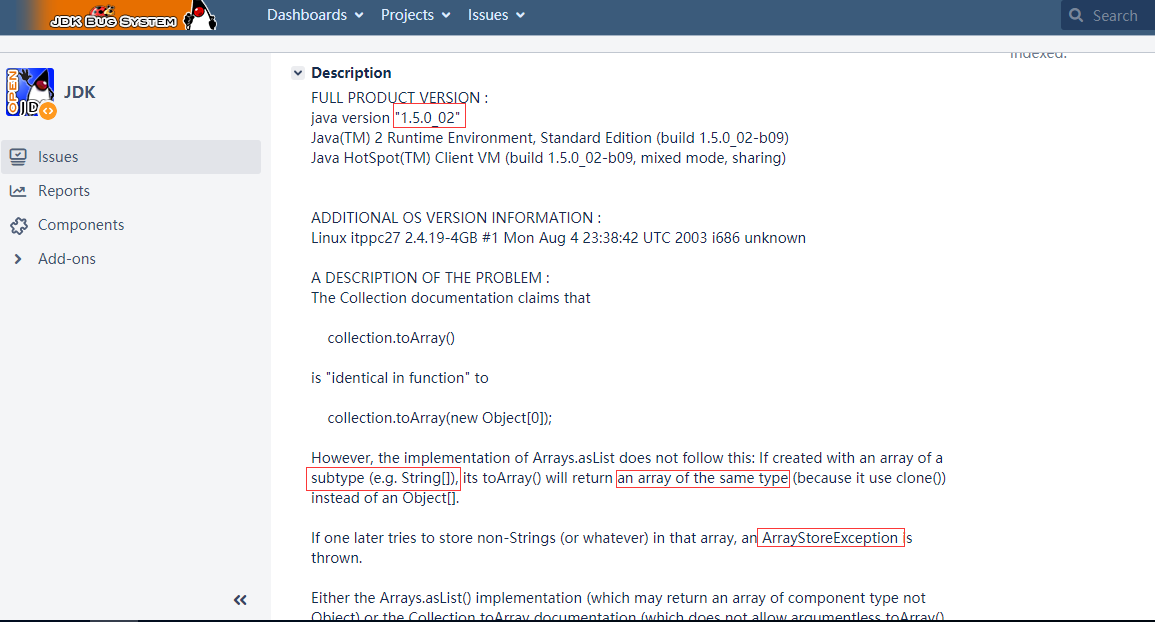
The maximum size of array to allocate (unless necessary). Some VMs
reserve some header words in an array. Attempts to
allocate larger arrays may result in OutOfMemoryError: Requested array
size exceeds VM
limit,翻译过来的重点就是虚拟机还需要存储头部字段,头部字段刚好占8个字节,所以如果要分配Integer.MAX_VALUE个容量的话就会导致OOM。
// Trims the capacity of this ArrayList instance to be the list's current size. publicvoidtrimToSize() { modCount++; if (size < elementData.length) { elementData = (size == 0) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size); } }
// increases the capacity of this ArrayList instance, if necessary, to ensure that it can hold at least the number of elements specified by the minimum capacity argument. publicvoidensureCapacity(int minCapacity) { if (minCapacity > elementData.length && !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA && minCapacity <= DEFAULT_CAPACITY)) { modCount++; grow(minCapacity); } }
privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out element count, and any hidden stuff intexpectedModCount= modCount; s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone() s.writeInt(size);
// Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); }
if (modCount != expectedModCount) { thrownewConcurrentModificationException(); } }
// Read in size, and any hidden stuff s.defaultReadObject();
// Read in capacity s.readInt(); // ignored
if (size > 0) { // like clone(), allocate array based upon size not capacity SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size); Object[] elements = newObject[size];
// Read in all elements in the proper order. for (inti=0; i < size; i++) { elements[i] = s.readObject(); }